
모델에 대한 성능 평가 단계
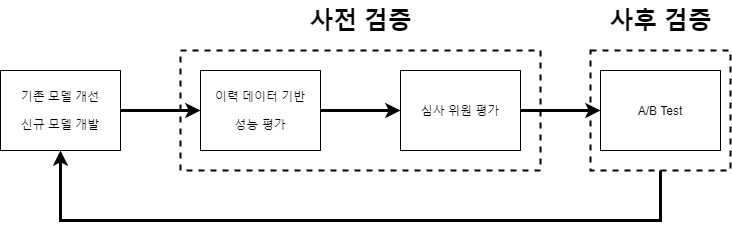
이론 데이터 기반 성능 평가 ( TODO )

심사 위원 평가
- 과거 이력 데이터 기반 평가의 한계
- 신규 추천 결과에 대한 사용자의 반응을 알 수 없음
- 정량적 평가
- 심사위원 평가
- 내부 인력, 외부 인력이 추천 결과의 품질을 평가
- Quality and Trust of Feedback'
A/B Test ( TODO)
- 서비스 KPI 지표로 평가 : 매출, PV, UV, CTR
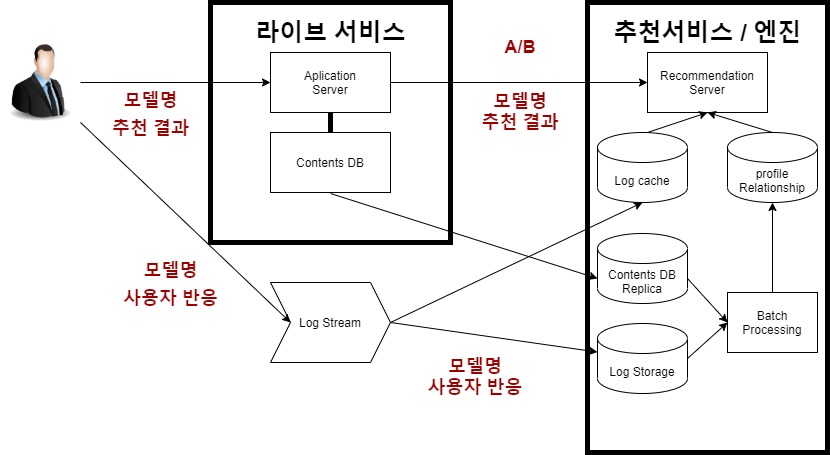
Rating Prediction 성능 평가
- 모델이 예측한 Rating과 사용자의 실제 Rating 차이를 계산

Top-K 추천 성능 평가
- 추천한 아이템 중 사용자에 의해 클릭된 아이템의 위치 및 개수를 이용하여 평가

| Confusion Matrix | Recommended(Predicted) | ||
| Positive | Negative | ||
| Relevant (Actual) |
Yes | True Positive(TP) | False Negative(FN) |
| NO | False Positive(FP) | True Negative(TN) | |
Precision = TP / TP + FP
Recall = TP / TP + FN
Precision@K & Recall@K
- 추천 결과의 개수가 K개일 떄의 Precision & Recall
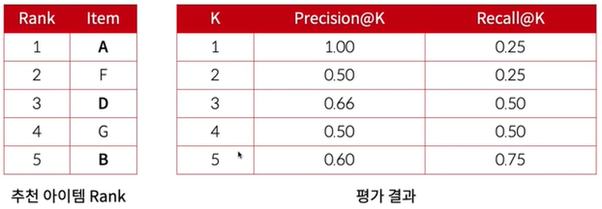
평가 데이터가 여러 개인 경우 각 평가 데이터에 대한 결과의 평균을 계산한다.
$$ Precision@K = \frac{1}{n}\ \sum_{i=1}^{n}Precision@K(t_{i}) $$
$$ Recall@K = \frac{1}{n}\ \sum_{i=1}^{n}Recall@K(t_{i}) $$
개인화 추천의 경우 각 개인에 대한 추천 결과를 평균하여 계산할 수 있음
Precision@K의 한계
- 추천된 아이템에서 만족한 아이템이 동일한 개수 일 때 추천된 순서에 따라서 값이 달라지지 않음.(추천 순서를 반영하지 않음)
- 추천 순서에 따라서 성능 평가가 달라지는 지표가 필요
Average Precision
- 추천된 아이템의 순서를 반영하여 관련성 있느 아이템이 상위에 추천될 때 더 높은 값을 가진다.
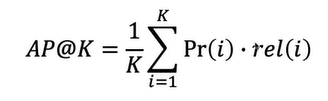
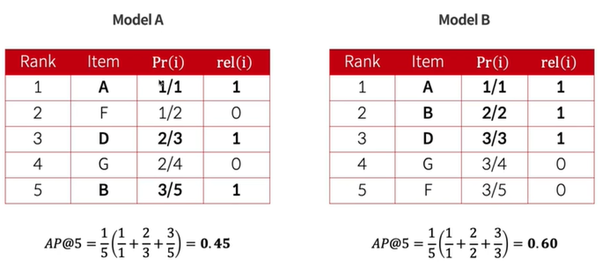
MAP: Mean Average Precision
- 평가 데이터가 여러 개인 경우 각 평가 데이터에 대한 결과의 평균을 계산한다.
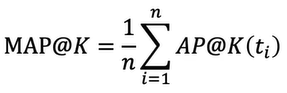
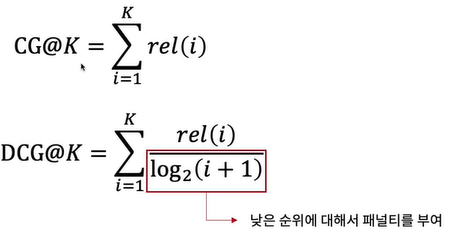
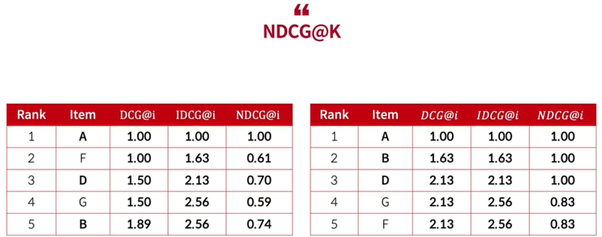
NDCG: Normalized Discounted Cumulative Gain
- AP와 마찬가지로 관련성이 높은 결과를 사우이에 추천하는지를 평가하는 지표
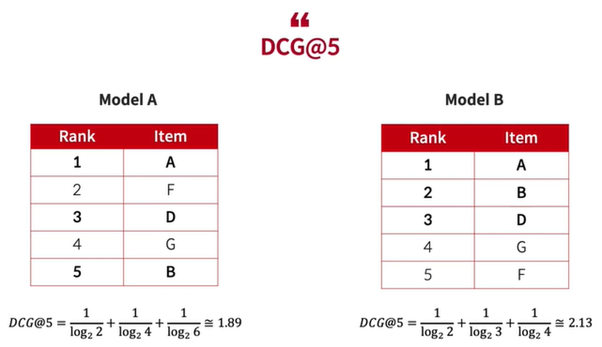
DCG@K는 K에 따라서 민감하게 변한다
NDCG
- K에 따른 변화를 최소화하기 위해 최선의 순서일 때의 DCG@K, 즉 I(deal)DCG@K를 구하고 이를 이용하여 정규화한 지표
NDCG@K - DCG@K / IDCG@K
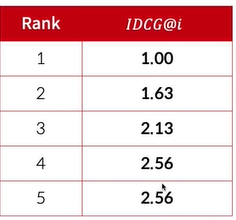
IDCG@K
- 예제에서는 A, B, C, D의 네 개의 아이템이 연관이 있기에 K가 1~5로 변할 때의 IDCG@K는 다음과 같다.
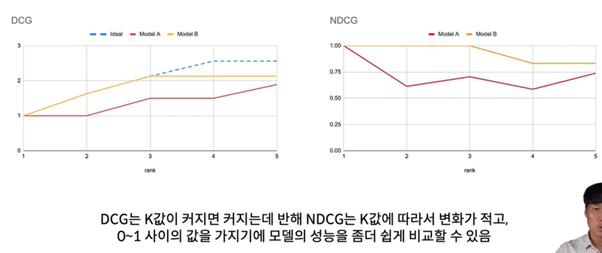
0~1사이의 값을 가지기에 모델의 성능을 좀 더 쉽게 비교할 수 있음.
'정리 > Machine Learning' 카테고리의 다른 글
| [FastCampus The RED 추천시스템] CBF (0) | 2021.11.11 |
|---|---|
| [FastCampus The RED 추천시스템] 추천 시스템을 돌릴 때 고려사항 (0) | 2021.11.10 |
| [FastCampus The RED 추천시스템] 개요 ~ 추천 시스템 분류 (0) | 2021.11.10 |
| [deeplearning] dataset & DataLoader (0) | 2021.11.09 |
| [kaggle - Google Brain - Ventilator Pressure Prediction] 4. predict, deploy, utility, etc (0) | 2021.11.09 |