
-
'ML Model Evaluation'이 의미하는 바를 알아보자.
-
2. Evaluation Metrics
-
2.1. Accuracy(정확도)
-
2.2. Recall ( 재현율 ) ( = True Positive Rate, Sensativity, 민감도)
-
2.3. Precision ( 정밀도 )
-
2.4. F1 Score
-
2.5. PB 곡선 ( precision - recall 곡선 )
-
2.6. ROC Curve ( receiver operating characteristic curve)
-
2.7. AUC - Area Under the ROC Curve
-
2.8. Multi-class ROC
'ML Model Evaluation'이 의미하는 바를 알아보자.
데이터 준비와 모델 학습은 누구나 머신러닝 작업 파이프라인에서 핵심적인 단계로 생각하지만, 학습된 모델의 퍼포먼스를 측정하는 것 또한 중요한 단계에 해당된다.
우리 모델은 배우지 않지만, 기억하고 있다. ML모델은 처음 만나는 데이터를 스스로 일반화 하여 받아들일 수 없ㄷ. 이를 시작하기 위해, 3개의 중요한 기준을 세우도록 한다.
Learnng: ML 모델 학습은 학습/이용 가능한 데이터에 대한 정확한 예측이 아닌, 미래 데이터에 대한 정확한 예측을 고려하여 진행되어야 한다.
Memorization: 제약된 데이터(training data)에 대한 퍼포먼스를 의미한다. 즉, training dataset에 대해서 overfitting하는 것을 의미
Generalization: 기존에 보이지 않았던 데이터에 대한 학습을 적용시키는 ML 모델의 수용력과 같다. generalization이 없다면, memorization만 존재하며, 학습이 되지 않았다는 것을 의미한다. 하지만, generalization이 좋은 specific인 것에 주목하자. ( 예를 들어, 동물원 동물 이미지에 대해 잘 훈련된 이미지 인식 모델은 차와 빌딩에 대해서는 제대로 일반화 되어 있지 않을 것이다.
2. Evaluation Metrics
- 자 이제, 학습된 모델의 퍼포먼스를 어떻게 측정하는 것이 좋을까?
- 머신러닝 모델의 종류마다 적절한 평가지표는 다르지만, Precision-recall과 같이 여러 머신러닝에서 통상적으로 유용하게 쓰이는 지표들에 대해서 이야기 해보자.
- 보통 가정을 내릴 때, 연구자에게 '중요하다고 판단'되는 명제를 P에다가 놓는다. ( 뭘 P로 놓느냐는 상대적인 것 같다)
- 아래의 confusion matrix에 대해서 알아보자
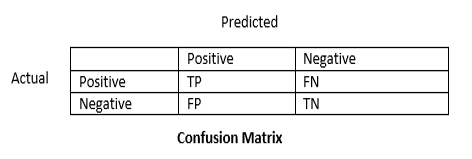
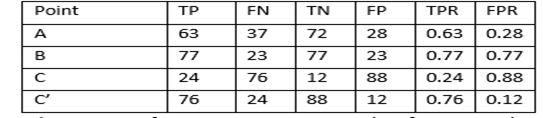
TP FN FP TN 의 네 가지 분류가 있고
T F
P N
으로 나뉨을 알 수 있다.
P : Positive - 내가 내린 명제가 '참'일 때
N : Negative - 내가 내린 명제가 '거짓'일 때
T : True - 내가 예측한 것이 맞을 때
N : False - 내가 예측한 것이 틀렸을 때
다시, 표를 보고 표에서 TP FN FP TN이 각각 무엇을 의미하는지 생각해 보는 시간을 가져보자.
이 표를 바탕으로 학습 모델의 성능을 계산해 보는 방법을 생각해 보자.
2.1. Accuracy(정확도)
- 전체 결과 중에서 정답을 맞춘 비율.
TP + TN / TP + TN + FP + FN
e.g.
이미지 중에서 고양이인지 아닌지 분류하는 모델을 가정해보자. 이 때, 마침 10개의 고양이 사진과, 90개의 강아지 사진이 테스트 데이터로 되었다고 가정해보자.
| 예측(Predict) | |||
| 실제(Actual) | 고양이 ㅇㅇ | 아님 ㄴㄴ | |
| 고양이 ㅇㅇ | 1 | 9 | |
| 아님 ㄴㄴ | 2 | 88 | |
Accuracy = ( 1 + 88 ) / ( 88 + 9 + 1 + 2 ) = 89 %이다
89%의 정확도를 보인다.
그런데, 만약 모든 사진이 고양이가 아니라고 판별하는 모델에 넣어보았다고 가정해보자. 그럼 어떻게 될까?
| 예측 | |||
| 실제 | 고양이 ㅇㅇ | 아님 ㄴㄴ | |
| 고양이 ㅇㅇ | 0 | 10 | |
| 아님 ㄴㄴ | 0 | 90 | |
Accuracy = ( 0 + 90 ) / ( 100 ) = 90% 의 정확도를 가진다.
그냥 모두 고양이가 아니라고 찍었을 뿐인데 천운으로 90%의 정확도를 보이며 기껏 머신러닝 돌린 것보다 더 높은 정확도를 보였다.
이러면 우리는 ML engineer보다는 도박사를 하는게 맞는게 아닐까?
라고 생각하지 말고, 이를 위해서 다른 지표들이 있다.
2.2. Recall ( 재현율 ) ( = True Positive Rate, Sensativity, 민감도)
실제로 Positive(P)인 것들 중 분류기가 '맞춘'(T) 비율
Recall = TP / ( TP + FN )
여기서 위 결과를 대입하면
M1_Recall = 1 / 10 => 10%
M2_Recall = 0 / 10 => 0%
이가 된다.
2.3. Precision ( 정밀도 )
명제가 맞다고 예측한 것 중, 정답이 되는 비율이다.
Precision = TP / TP + FP
M1_Precision = 1 / 3 ==> 33.3%
M2_Precision = 0 / 0 ==> 0 %
이 된다.
2.4. F1 Score
F1 = (2 * Precision * Recall ) / ( Precision + Recall )
M1_F1 = ( 2 * 0.1 * 0.33 ) / (0. 43) = ?
M!_F2 = 0
2.5. PB 곡선 ( precision - recall 곡선 )
confidence level에 대한 threshold 값의 변화에 의한 물체 검출기의 성능을 평가하는 방법이다.
보통, Precision과 recall은 반대되는 경향을 보여서, recall이 증가하면, precision이 감소하는 경향을 보인다.
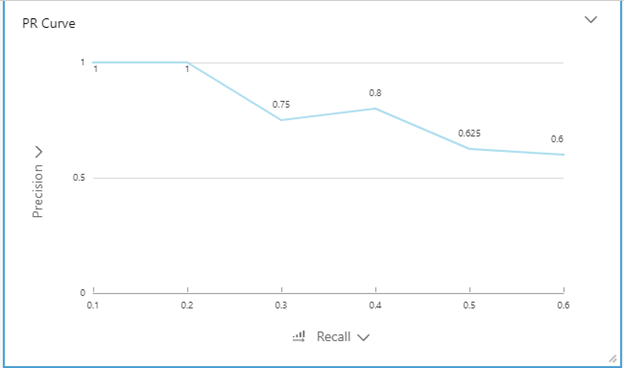
PR curve
분석 domain별로 precision이 중요할 때도 있고, recall이 중요할 때도 있다고 한다.
2.6. ROC Curve ( receiver operating characteristic curve)
분류기의 분류 능력을 그래프 좌표로 표현하는 방법이다.
ROC curve는 FP 비율에 대한 TP 비율을 여러 Threshold로 조정하여 표로 그려서 표현한다.
TPR은 Recall 또는 민감도, FPR은 (1 - 특이도).
x축(Specificity) : FPR = FP / ( FP + TN )
y축(Sensativity): TPR = TP / ( TP + FN )
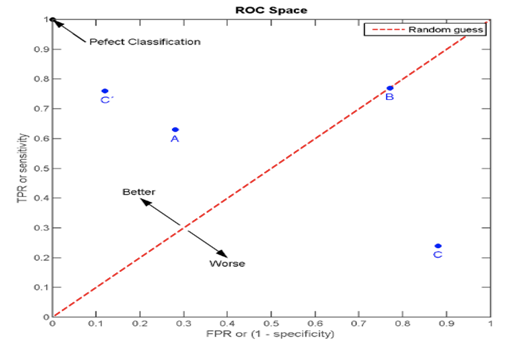
점 A, B, C, C'는 서로 다른 TPR & FPR을 갖고 그래프에 표현한 것.
점 (0, 0) - Positivie 결과가 하나도 없는 경우
점 (0, 1) - FP의 결과는 하나도 없고, TP만 있는 결과
ROC의 장점 중 하나는 class 분포에 민감하지 않다는 점이다.
test set에서 positive와 negative의 비율이 바뀌어도 ROC곡선은 변하지 않는다. 이러한 ROC curve의 특성을 class skew independence라고 한다.
(추가. from. statquest)
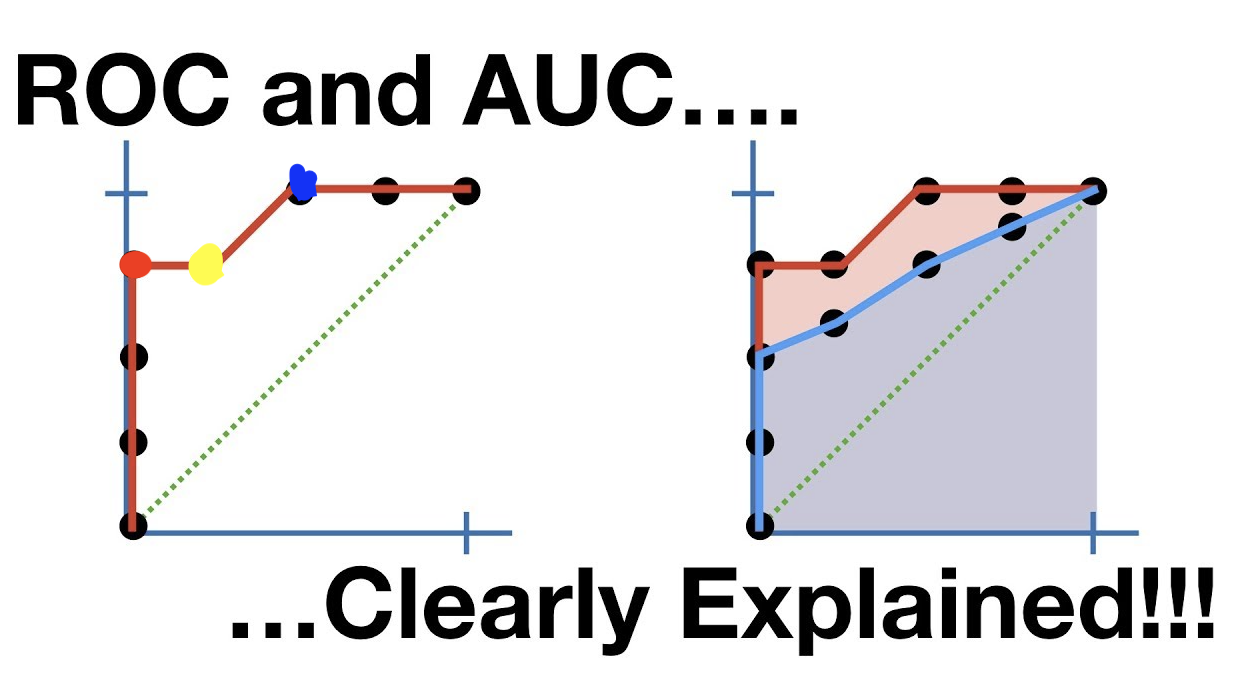
여기서 알 수 있는 것은
노란점보다 빨간점의 성능이 더 좋다는 것이고,
FPR에 대해서 얼마나 관대하냐에 따라서 빨간점을 선택할 것인지, 파란점을 선택할 것인지 생각해볼 수 있다.
ROC를 어떻게 써먹냐 모호했었는데, 이 영상보고 바로 bammmm 했다.
* negative 요인이 많은 경우에는 precision 사용하는게 더 좋을 거라고 한다. 그 이유는 FN에 영향을 받지 않기 때문에...
예를 들어, 정말 드문 경우의 병을 진단할 때 씀
그런데 이거를 수치로 어떻게 표현할 수 있을까? 이 때 나온 것이 AUC이다.
2.7. AUC - Area Under the ROC Curve
ROC 커브는 classifier의 성능의 2차원적인 표현이었다.
classifier들을 비교하고자, ROC performance 수치를 모델의 예상 성능을 나타내는 단일 스칼라값으로 정리하여 볼 수 있는데, 이 때 일반적인 방법은 ROC curve 아래 면적을 계산하는 방법이고 줄여서 AUC라고 한다.
AUC는 그래프의 사각형 영역의 일부 영역의 비율이기 때문에, 0 ~ 1의 범위를 갖고 있다.
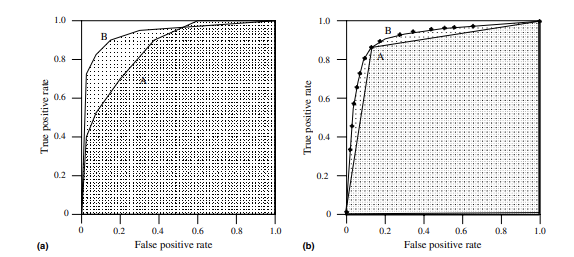
(그래프에 대한 설명이라 그대로 퍼옴)
위의 차트a 는 AUC를 A와 B로 표현한 것이다.
분류기 B는 더 큰 영역을 가지고 있으므로, 평균적으로 더 나은 퍼포먼스를 낸다고 해석할 수 있다.
차트b는 이진분류기 A와 스코어링 분류기 B의 AUC를 한 표로 나타낸 것이다.
차트a를 보면, 높은 AUC값을 가지는 분류기가 그렇지 못한 분류기보다
ROC공간의 특정 영역에서는 성능이 저하될 수도 있다는것을 확인할 수 있다.
A가 일부 영역에서는 더 좋은 성능을 보이지만, 분류기 B가 FP비율> 0.6일때를 제외하고는 일반적으로 A보다 성능이 낫다고 볼 수 있다.
이처럼 AUC는 예측에 대한 바람직한 기준이 필요할때 종종 사용된다.
AUC는 아래 2가지 이유로 바람직한 지표라고 생각할 수 있다.
- AUC는 고정수치이기때문에, 얼마나 모델이 잘 예측하는지 절대적 수치로 측정할 수 있다.
- AUC는 분류 임계치가 고정되어있기에, 모델의 분류 임계점이 어떠한지에 관계없이 모델이 잘 예측하는지 측정할 수 있다.
2.8. Multi-class ROC
- 2개 이상의 분류 클래스에서, 분류 문제는 더욱 복잡해진다.
(이 부분은 아직 배운 부분도 아니고, 블로그를 읽어도 이해가 가지 않으므로 추후 추가하겠음)
TODO)
왜? positive를 예측한 것을 활용한 것들 뿐인 ROC curve가 성능을 평가할 수 있는 거지? negative 예측한 거는 다 어디감
Ref)
강추 - https://www.youtube.com/watch?v=4jRBRDbJemM
(번역) https://velog.io/@crescent702/%EB%B2%88%EC%97%AD-Evaluation-Metrics-for-Machine-Learning-Models
(원본) https://heartbeat.fritz.ai/evaluation-metrics-for-machine-learning-models-d42138496366
'정리 > Machine Learning' 카테고리의 다른 글
| [kaggle - Google Brain - Ventilator Pressure Prediction] 2. data preprocess ~ define architecture ( LSTM ) (0) | 2021.11.08 |
|---|---|
| [kaggle - Google Brain - Ventilator Pressure Prediction] 1. Data load ~ EDA (0) | 2021.11.08 |
| [Deep Learning] Deep Learning 주요 순서 정리 (0) | 2021.11.05 |
| [DL 기본] 210914 수업 내용 정리 (0) | 2021.09.14 |
| [머신러닝 모델] Decision Tree (0) | 2021.08.31 |
'ML Model Evaluation'이 의미하는 바를 알아보자.
데이터 준비와 모델 학습은 누구나 머신러닝 작업 파이프라인에서 핵심적인 단계로 생각하지만, 학습된 모델의 퍼포먼스를 측정하는 것 또한 중요한 단계에 해당된다.
우리 모델은 배우지 않지만, 기억하고 있다. ML모델은 처음 만나는 데이터를 스스로 일반화 하여 받아들일 수 없ㄷ. 이를 시작하기 위해, 3개의 중요한 기준을 세우도록 한다.
Learnng: ML 모델 학습은 학습/이용 가능한 데이터에 대한 정확한 예측이 아닌, 미래 데이터에 대한 정확한 예측을 고려하여 진행되어야 한다.
Memorization: 제약된 데이터(training data)에 대한 퍼포먼스를 의미한다. 즉, training dataset에 대해서 overfitting하는 것을 의미
Generalization: 기존에 보이지 않았던 데이터에 대한 학습을 적용시키는 ML 모델의 수용력과 같다. generalization이 없다면, memorization만 존재하며, 학습이 되지 않았다는 것을 의미한다. 하지만, generalization이 좋은 specific인 것에 주목하자. ( 예를 들어, 동물원 동물 이미지에 대해 잘 훈련된 이미지 인식 모델은 차와 빌딩에 대해서는 제대로 일반화 되어 있지 않을 것이다.
2. Evaluation Metrics
- 자 이제, 학습된 모델의 퍼포먼스를 어떻게 측정하는 것이 좋을까?
- 머신러닝 모델의 종류마다 적절한 평가지표는 다르지만, Precision-recall과 같이 여러 머신러닝에서 통상적으로 유용하게 쓰이는 지표들에 대해서 이야기 해보자.
- 보통 가정을 내릴 때, 연구자에게 '중요하다고 판단'되는 명제를 P에다가 놓는다. ( 뭘 P로 놓느냐는 상대적인 것 같다)
- 아래의 confusion matrix에 대해서 알아보자
TP FN FP TN 의 네 가지 분류가 있고
T F
P N
으로 나뉨을 알 수 있다.
P : Positive - 내가 내린 명제가 '참'일 때
N : Negative - 내가 내린 명제가 '거짓'일 때
T : True - 내가 예측한 것이 맞을 때
N : False - 내가 예측한 것이 틀렸을 때
다시, 표를 보고 표에서 TP FN FP TN이 각각 무엇을 의미하는지 생각해 보는 시간을 가져보자.
이 표를 바탕으로 학습 모델의 성능을 계산해 보는 방법을 생각해 보자.
2.1. Accuracy(정확도)
- 전체 결과 중에서 정답을 맞춘 비율.
TP + TN / TP + TN + FP + FN
e.g.
이미지 중에서 고양이인지 아닌지 분류하는 모델을 가정해보자. 이 때, 마침 10개의 고양이 사진과, 90개의 강아지 사진이 테스트 데이터로 되었다고 가정해보자.
| 예측(Predict) | |||
| 실제(Actual) | 고양이 ㅇㅇ | 아님 ㄴㄴ | |
| 고양이 ㅇㅇ | 1 | 9 | |
| 아님 ㄴㄴ | 2 | 88 | |
Accuracy = ( 1 + 88 ) / ( 88 + 9 + 1 + 2 ) = 89 %이다
89%의 정확도를 보인다.
그런데, 만약 모든 사진이 고양이가 아니라고 판별하는 모델에 넣어보았다고 가정해보자. 그럼 어떻게 될까?
| 예측 | |||
| 실제 | 고양이 ㅇㅇ | 아님 ㄴㄴ | |
| 고양이 ㅇㅇ | 0 | 10 | |
| 아님 ㄴㄴ | 0 | 90 | |
Accuracy = ( 0 + 90 ) / ( 100 ) = 90% 의 정확도를 가진다.
그냥 모두 고양이가 아니라고 찍었을 뿐인데 천운으로 90%의 정확도를 보이며 기껏 머신러닝 돌린 것보다 더 높은 정확도를 보였다.
이러면 우리는 ML engineer보다는 도박사를 하는게 맞는게 아닐까?
라고 생각하지 말고, 이를 위해서 다른 지표들이 있다.
2.2. Recall ( 재현율 ) ( = True Positive Rate, Sensativity, 민감도)
실제로 Positive(P)인 것들 중 분류기가 '맞춘'(T) 비율
Recall = TP / ( TP + FN )
여기서 위 결과를 대입하면
M1_Recall = 1 / 10 => 10%
M2_Recall = 0 / 10 => 0%
이가 된다.
2.3. Precision ( 정밀도 )
명제가 맞다고 예측한 것 중, 정답이 되는 비율이다.
Precision = TP / TP + FP
M1_Precision = 1 / 3 ==> 33.3%
M2_Precision = 0 / 0 ==> 0 %
이 된다.
2.4. F1 Score
F1 = (2 * Precision * Recall ) / ( Precision + Recall )
M1_F1 = ( 2 * 0.1 * 0.33 ) / (0. 43) = ?
M!_F2 = 0
2.5. PB 곡선 ( precision - recall 곡선 )
confidence level에 대한 threshold 값의 변화에 의한 물체 검출기의 성능을 평가하는 방법이다.
보통, Precision과 recall은 반대되는 경향을 보여서, recall이 증가하면, precision이 감소하는 경향을 보인다.
PR curve
분석 domain별로 precision이 중요할 때도 있고, recall이 중요할 때도 있다고 한다.
2.6. ROC Curve ( receiver operating characteristic curve)
분류기의 분류 능력을 그래프 좌표로 표현하는 방법이다.
ROC curve는 FP 비율에 대한 TP 비율을 여러 Threshold로 조정하여 표로 그려서 표현한다.
TPR은 Recall 또는 민감도, FPR은 (1 - 특이도).
x축(Specificity) : FPR = FP / ( FP + TN )
y축(Sensativity): TPR = TP / ( TP + FN )
점 A, B, C, C'는 서로 다른 TPR & FPR을 갖고 그래프에 표현한 것.
점 (0, 0) - Positivie 결과가 하나도 없는 경우
점 (0, 1) - FP의 결과는 하나도 없고, TP만 있는 결과
ROC의 장점 중 하나는 class 분포에 민감하지 않다는 점이다.
test set에서 positive와 negative의 비율이 바뀌어도 ROC곡선은 변하지 않는다. 이러한 ROC curve의 특성을 class skew independence라고 한다.
(추가. from. statquest)
여기서 알 수 있는 것은
노란점보다 빨간점의 성능이 더 좋다는 것이고,
FPR에 대해서 얼마나 관대하냐에 따라서 빨간점을 선택할 것인지, 파란점을 선택할 것인지 생각해볼 수 있다.
ROC를 어떻게 써먹냐 모호했었는데, 이 영상보고 바로 bammmm 했다.
* negative 요인이 많은 경우에는 precision 사용하는게 더 좋을 거라고 한다. 그 이유는 FN에 영향을 받지 않기 때문에...
예를 들어, 정말 드문 경우의 병을 진단할 때 씀
그런데 이거를 수치로 어떻게 표현할 수 있을까? 이 때 나온 것이 AUC이다.
2.7. AUC - Area Under the ROC Curve
ROC 커브는 classifier의 성능의 2차원적인 표현이었다.
classifier들을 비교하고자, ROC performance 수치를 모델의 예상 성능을 나타내는 단일 스칼라값으로 정리하여 볼 수 있는데, 이 때 일반적인 방법은 ROC curve 아래 면적을 계산하는 방법이고 줄여서 AUC라고 한다.
AUC는 그래프의 사각형 영역의 일부 영역의 비율이기 때문에, 0 ~ 1의 범위를 갖고 있다.
(그래프에 대한 설명이라 그대로 퍼옴)
위의 차트a 는 AUC를 A와 B로 표현한 것이다.
분류기 B는 더 큰 영역을 가지고 있으므로, 평균적으로 더 나은 퍼포먼스를 낸다고 해석할 수 있다.
차트b는 이진분류기 A와 스코어링 분류기 B의 AUC를 한 표로 나타낸 것이다.
차트a를 보면, 높은 AUC값을 가지는 분류기가 그렇지 못한 분류기보다
ROC공간의 특정 영역에서는 성능이 저하될 수도 있다는것을 확인할 수 있다.
A가 일부 영역에서는 더 좋은 성능을 보이지만, 분류기 B가 FP비율> 0.6일때를 제외하고는 일반적으로 A보다 성능이 낫다고 볼 수 있다.
이처럼 AUC는 예측에 대한 바람직한 기준이 필요할때 종종 사용된다.
AUC는 아래 2가지 이유로 바람직한 지표라고 생각할 수 있다.
- AUC는 고정수치이기때문에, 얼마나 모델이 잘 예측하는지 절대적 수치로 측정할 수 있다.
- AUC는 분류 임계치가 고정되어있기에, 모델의 분류 임계점이 어떠한지에 관계없이 모델이 잘 예측하는지 측정할 수 있다.
2.8. Multi-class ROC
- 2개 이상의 분류 클래스에서, 분류 문제는 더욱 복잡해진다.
(이 부분은 아직 배운 부분도 아니고, 블로그를 읽어도 이해가 가지 않으므로 추후 추가하겠음)
TODO)
왜? positive를 예측한 것을 활용한 것들 뿐인 ROC curve가 성능을 평가할 수 있는 거지? negative 예측한 거는 다 어디감
Ref)
강추 - https://www.youtube.com/watch?v=4jRBRDbJemM
(번역) https://velog.io/@crescent702/%EB%B2%88%EC%97%AD-Evaluation-Metrics-for-Machine-Learning-Models
(원본) https://heartbeat.fritz.ai/evaluation-metrics-for-machine-learning-models-d42138496366
'정리 > Machine Learning' 카테고리의 다른 글
| [kaggle - Google Brain - Ventilator Pressure Prediction] 2. data preprocess ~ define architecture ( LSTM ) (0) | 2021.11.08 |
|---|---|
| [kaggle - Google Brain - Ventilator Pressure Prediction] 1. Data load ~ EDA (0) | 2021.11.08 |
| [Deep Learning] Deep Learning 주요 순서 정리 (0) | 2021.11.05 |
| [DL 기본] 210914 수업 내용 정리 (0) | 2021.09.14 |
| [머신러닝 모델] Decision Tree (0) | 2021.08.31 |