
728x90
1. data preprocess
- dataset - sample과 target을 저장하는 구조.
- DataLoader - sample에 쉽게 접근할 수 있도록 dataset을 순회 가능한(iterable) 객체로 감싼다.
import torch
from torch.utils.data import Dataset
# dataset은 sample과 정답을 저장
# DataLoader는 sample에 쉽게 접근할 수 있도록 dataset을 순회 가능한 객체로 감싼다.
class VentilatorDataset(Dataset):
def __init__(self, df):
if 'pressure' not in df.columns: # pressure가 없는 test / validation df인 경우, 0으로 채운다.
df['pressure'] = 0
# df를 breath_id로 groupby시키고, 안에 내용물들을 다 list로 만든다음, reset_index
self.df = df.groupby('breath_id').agg(list).reset_index()
# r, c, u_in, u_in_numsum, u_out을 하나의 리스트에 넣고 그 리스트를 df의 row로 형성한다.
self.prepare_data()
def __len__(self):
return self.df_shape[0]
# dataframe에 있는 r, c, U_in, u_in_누적합, u_out 순으로 리스트로 나타냄
def prepare_data(self):
self.pressures = np.array(self.df['pressure'].values.tolist())
rs = np.array(self.df['R'].values.tolist())
cs = np.array(self.df['C'].values.tolist())
u_ins = np.array(self.df['u_in'].values.tolist())
self.u_outs = np.array(self.df['u_out'].values.tolist())
# https://michigusa-nlp.tistory.com/22 (75450, 80) --> (75450, 1, 80) (# breath_id, 1, # breath_id values)
self.inputs = np.concatenate([
rs[:, None], # (75450, 80) --> (75450, 1, 80) (# breath_id, 1, # breath_id values)
cs[:, None],
u_ins[:, None],
np.cumsum(u_ins, 1)[:, None],
self.u_outs[:, None]],
1).transpose(0, 2, 1) # (75450, 5, 80)[breath_id 갯수, input별, in breath_id] --> (75450, 80, 5)
def __getitem__(self, idx):
data = {
'input' : torch.tensor(self.inputs[idx], dtype=torch.float),
'u_out' : torch.tensor(self.u_outs[idx], dtype=torch.float),
'p' : torch.tensor(self.pressures[idx], dtype=torch.float)
}
return data하나씩 살펴보자.
...
# df를 breath_id로 groupby시키고, 안에 내용물들을 다 list로 만든다음, reset_index
self.df = df.groupby('breath_id').agg(list).reset_index()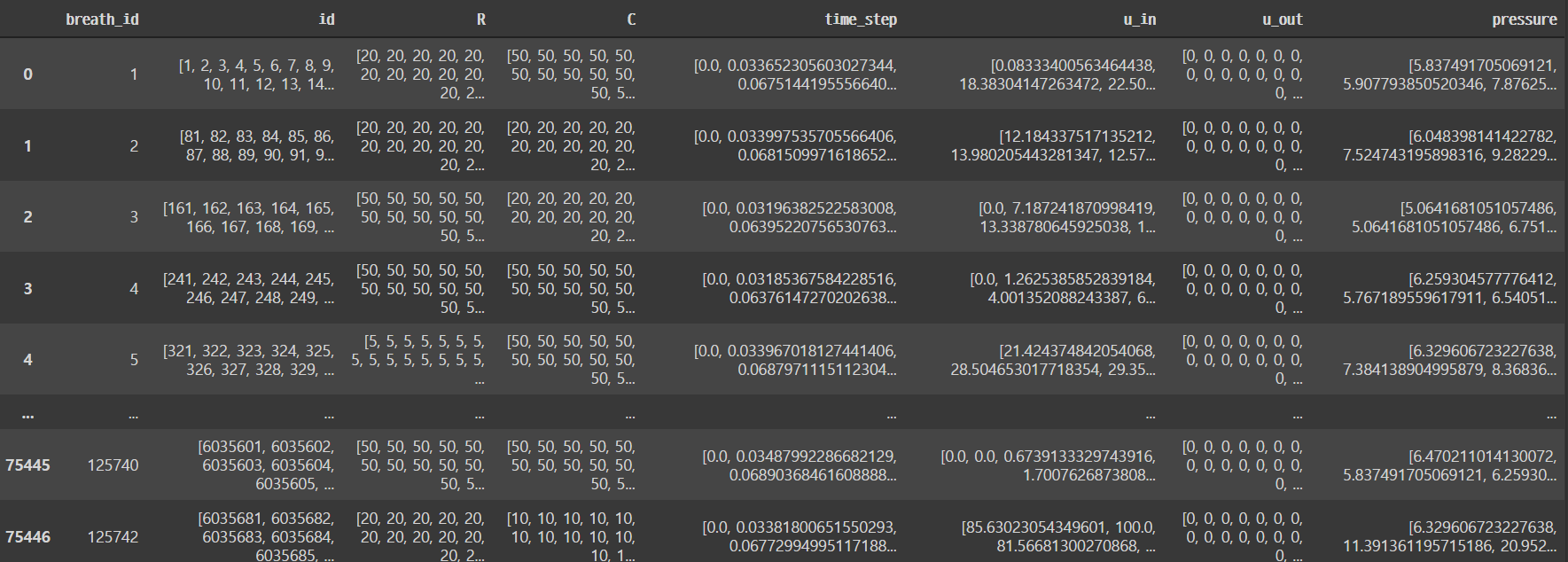
id, R, C 등 feature들이 breath_id별로 list화 되어서 return
def prepare_data(self):
self.pressures = np.array(self.df['pressure'].values.tolist())
rs = np.array(self.df['R'].values.tolist())
cs = np.array(self.df['C'].values.tolist())
u_ins = np.array(self.df['u_in'].values.tolist())
self.u_outs = np.array(self.df['u_out'].values.tolist())
# https://michigusa-nlp.tistory.com/22 (75450, 80) --> (75450, 1, 80) (# breath_id, 1, # breath_id values)
self.inputs = np.concatenate([
rs[:, None], # (75450, 80) --> (75450, 1, 80) (# breath_id, 1, # breath_id values)
cs[:, None],
u_ins[:, None],
np.cumsum(u_ins, 1)[:, None],
self.u_outs[:, None]],
1).transpose(0, 2, 1) # (75450, 5, 80)[breath_id 갯수, input별, in breath_id] --> (75450, 80, 5)이건 눈으로 직접 보려면 좀 빡세다.
대신에 실제 작업할 때는 각 column의 갯수를 보면서 어떤 의미인지 파악을 하면 더 좋을 것 같다.
df['R'].values

df['R'].values.tolist() : numpy array를list로 바꿔줌
* shape가 (75450, 80)이다.
'''
[[20,
20,
20,
20,
20,
20,
...
'''rs[:, None]
* (75450, 80) --> (75450, 1, 80)
np.concatenate([ rs[:, None], ... ], 1)
* (75450, 1, 80) + (75450, 1, 80) + (75450, 1, 80) + (75450, 1, 80) + (75450, 1, 80) = (75450, 5, 80)
만약 axis = 0 이면
(75450, 1, 80) + (75450, 1, 80) + (75450, 1, 80) + (75450, 1, 80) + (75450, 1, 80) = (75450 * 5, 1, 80)
.transpose(0, 2, 1)
(75450, 5, 80) --> (75450, 80, 5)
2. define architecture
이번 프로젝트에서는 LSTM 모델을 쓸 예정
따라서 RNN 모델을 정의하자.
import torch
import torch.nn as nn
class RNNModel(nn.Module):
def __init__(
self,
input_dim = 4,
lstm_dim = 256,
dense_dim = 256,
logit_dim = 256,
num_classes = 1
):
super().__init__()
self.mlp = nn.Sequential( # mlp = multi layer perceptron // 차원을 늘리기 위함이었구만
nn.Linear(input_dim, dense_dim // 2), # 4 --> 128
nn.ReLU(),
nn.Linear(dense_dim // 2, dense_dim), # 128 --> 256
nn.ReLU()
)
self.lstm = nn.LSTM(dense_dim, lstm_dim, batch_first=True, bidirectional=True) # dense_dim = input_dimension // lstm_dim = hidden_size
self.logits = nn.Sequential(
nn.Linear(lstm_dim * 2, logit_dim),
nn.ReLU(),
nn.Linear(logit_dim, num_classes)
)
def forward(self, x): # forward propagation ( = feed forward )
features = self.mlp(x) # mlp ( 4 --> 256)
features, _ = self.lstm(features) # lstm
pred = self.logits(features) # logits(이건 뭘까) ( 512 --> 1 )
return pred* 참고로 LSTM에서
bidirectional = True
이기 때문에 LSTM을 거치면 차원이 2배가 된다.
따라서 logits에서 lstm_dim*2를 한 것.
728x90
'정리 > Machine Learning' 카테고리의 다른 글
| [kaggle - Google Brain - Ventilator Pressure Prediction] 4. predict, deploy, utility, etc (0) | 2021.11.09 |
|---|---|
| [kaggle - Google Brain - Ventilator Pressure Prediction] 3. compiling model ~ fit model (0) | 2021.11.08 |
| [kaggle - Google Brain - Ventilator Pressure Prediction] 1. Data load ~ EDA (0) | 2021.11.08 |
| [Deep Learning] Deep Learning 주요 순서 정리 (0) | 2021.11.05 |
| [DL 기본] 210914 수업 내용 정리 (0) | 2021.09.14 |