
Title: Generative Adversarial Networks
Link: https://arxiv.org/abs/1406.2661

generative adversarial network(GAN) 논문은 2014년에 발표한 논문이다. GAN을 제안한 Ian goodfellow는 GAN의 구조를 마치 지폐 위조범과 위조를 적발하는 경찰 간의 게임에 비유했다. 위조범은 위조 이미지(=지폐)를 생성(Generator)해야 하고, 경찰은 위조범이 만든 이미지와 실제 이미지를 구분(discriminator)해야 한다. 이러한 경쟁이 지속되다 보면 위조범은 진짜와 가짜를 구분할 수 없게 만들 수 있고, 경찰은 최악의 상황인 50%의 확률로 지폐를 구분할 수 밖에 없게 된다.(사실상 참/거짓 문제에서 50%는 찍는 것과 다름없다고 보면 될 듯하다.) 이 때, 경찰인 구분기(discriminator)와 지폐 위조범인 생성기(generator)는 discriminator의 loss를 두고 경쟁하는, minimax two-palyer game을 한다고 생각하면 된다. 임의의 함수 G와 D의 공간에서, G와 D가 multi layer perceptron으로 정의된 상황에서, 전체 시스템은 반복적으로 학습된다.
여기서 주목할 점은 학습이나 샘플 생성 중에 다른 생성 AI(VAE, diffusion 등)에서 볼 수 있는 markov chain이나 근사 추론 네트워크가 필요하지 않다는 것이다.
Introduction
adversarial nets framework에서 generator(G)는 그의 적과 맞선다. 그 '적'이 누구냐면, 샘플이 G가 만든 것인지, 혹은 실제 데이터 분포 상에 존재하는 것인지 구분해야 하는 D이다. G는 마치 위조 화폐를 만들어 발각되지 않고 사용하려는 위조범과 유사하다. 그리고 D는 위조 화폐를 탐지하려는 경찰과 유사하다. 이 게임은 위조품이 진품과 구별될 수 없을때까지 양 팀의 방법을 개선하도록 유도된다.
이 framework에서는 다양한 종류의 모델과 최적과 알고리즘을 적용시켜 여러 특정 학습 알고리즘을 만들어 볼 수 있다. 이 논문에서는 생성 모델 G는 다층 퍼셉트론에 랜덤 노이즈를 통과시켜 샘플을 생성하는 특수한 경우와 판별 모델 D도 다층 퍼셉트론을 통과시켜 이를 구분하는 모습을 볼 수 있다. 저자는 이러한 경우를 adversarial net이라고 부른다. 이 경우에 매우 성공적인 back propagation 및 dropout 알고리즘 만 사용해서 두 모델을 학습시키고 forward propagation만 사용해서 G가 샘플링할 수 있다. 앞에서 말했듯이 여기서는 다른 생성 ai에서 활용되는 markov chain이나 근사 추론을 사용하지 않는다.
Adversarial nets
적대적 모델링 프레임워크는 모델이 multylayer perceptron일 때 직관적으로 사용이 가능하며, G와 D에 대한 목적함수는 다음과 같다.
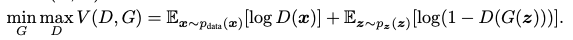
여기서 실제 데이터 x에 대한 G의 학습을 위해서 input noise variable을 z~p_z(z)로 정의하고 x domain에 대한 data space의 mapping을 G(z; Θ_g)로 표현했다. 여기서 G는 Θ_g를 parameter로 하는 다층 신경망에 의해 표현되는 미분 가능한 함수이다. 그리고 분류기 D는 single scalar를 출력하며, D(x;Θ_d)로 표현되는 다층 신경망이다. D(x)는 x가 생성기보다 실제 데이터에서 유래됐을지에 대한 확률을 의미한다.(실제 데이터라면 1에 가깝고, 아니라면 0에 가까울 것이다.) 즉 위 식은 D는 실제 데이터와 가짜 데이터를 잘 구분할 수 있도록 목적식을 최대화해야 하고, G는 D를 방해하기 위해 전체 목적식을 최소화해야 하는 two-player minimax game을 의미한다.
이 minimax game에 대한 알고리즘은 다음과 같다.

- k번 반복
- random noise sample {z, …}에 대한 이미지 생성
- 실제 데이터 {x}에 대한 샘플
- stochastic gradient를 올리는 방향으로 discriminator update
- random noise sample {z, …}에 대한 이미지 생성
- stochastic gradient를 내리는 방향으로 generator를 update
- end for
Theoretical Results


Experiments
- MNIST, Toronto Face Database(TFD), CIFAR-10에 대해 학습을 진행하였다.
- G는 RELU, sigmoid를 혼합했고, D는 maxout activatio을 사용함.
- D를 학습 시킬때는 dropout을 사용함
- 이론상의 framework에서는 generator의 중간층에 dropout과 noise를 허용하지 않지만, 이 실험에서는 generator net의 맨 하위계층에 input으로 noise를 사용했다고 한다.
- 이 실험에서는 G로 생성된 sample에 Gaussian Parzen window를 맞추고, 해당 분포에 따른 log-likelihood를 알려줌으로써 Pg에 따른 test set data를 추정했다.
- 결과로, G가 생성해낸 sample이 기존의 방법으로 만든 sample들보다 좋다고 할 수는 없지만, 더 나은 생성모델과 경쟁할 수 있으며, adversarial framework의 잠재력을 강조함.
Advantages and disadvantages
장점
- markov chain이 필요없고, gradient를 계산하기 위해 back-propagation만 사용됨
- 학습 중 inference가 필요 없음
- 다양한 함수들이 모델에 접목될 수 잇음
- markov chain을 쓸 때보다 훨씬 선명한 이미지를 얻을 수 있음
단점
- pg(x)가 명시적으로 존재하지 않음
- D와 G가 균형을 잘 막춰 성능이 향상되어야 함.(D가 학습이 되기 전에 G를 먼저 너무 학습시키면 z 데이터를 너무 많이 붕괴시킬 수 있다고 한다.)
Conclusions and future work
- conditional generative model로 발전시킬 수 있다.
- learned approximate inference는 주어진 x를 예측하여 수행될 수 있다.
- parameter를 공유하는 conditilnals model을 학습해서 다른 conditionals model을 근사적으로 모델링할 수 ㅣㅇㅆ다.
- seme-supervised learning, 즉, 레이블이 제한되어 있는 데이터를 사용할 때, classifier의 성능을 향상시킬 수 있다.
- 효율성 개선. G와 D를 조정하는 더 나은 방법 또는 학습하는 동안 sample z에 대한 더 나은 분포를 결정함으로써 학습의 속도를 높일 수 있다.
샘플 코드
GAN for MNIST Tutorial
Colaboratory notebook
colab.research.google.com
참고 자료
https://arxiv.org/abs/1406.2661
https://tobigs.gitbook.io/tobigs/deep-learning/computer-vision/gan-generative-adversarial-network
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] Vision Transformer[2] 구현 (0) | 2023.08.02 |
|---|---|
| [논문리뷰] Vision Transformer[1] 논문 정리 (0) | 2023.08.01 |
| [논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.07.04 |
| [논문리뷰] You only look once(YOLO) (0) | 2023.06.29 |
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |
Title: Generative Adversarial Networks
Link: https://arxiv.org/abs/1406.2661
generative adversarial network(GAN) 논문은 2014년에 발표한 논문이다. GAN을 제안한 Ian goodfellow는 GAN의 구조를 마치 지폐 위조범과 위조를 적발하는 경찰 간의 게임에 비유했다. 위조범은 위조 이미지(=지폐)를 생성(Generator)해야 하고, 경찰은 위조범이 만든 이미지와 실제 이미지를 구분(discriminator)해야 한다. 이러한 경쟁이 지속되다 보면 위조범은 진짜와 가짜를 구분할 수 없게 만들 수 있고, 경찰은 최악의 상황인 50%의 확률로 지폐를 구분할 수 밖에 없게 된다.(사실상 참/거짓 문제에서 50%는 찍는 것과 다름없다고 보면 될 듯하다.) 이 때, 경찰인 구분기(discriminator)와 지폐 위조범인 생성기(generator)는 discriminator의 loss를 두고 경쟁하는, minimax two-palyer game을 한다고 생각하면 된다. 임의의 함수 G와 D의 공간에서, G와 D가 multi layer perceptron으로 정의된 상황에서, 전체 시스템은 반복적으로 학습된다.
여기서 주목할 점은 학습이나 샘플 생성 중에 다른 생성 AI(VAE, diffusion 등)에서 볼 수 있는 markov chain이나 근사 추론 네트워크가 필요하지 않다는 것이다.
Introduction
adversarial nets framework에서 generator(G)는 그의 적과 맞선다. 그 '적'이 누구냐면, 샘플이 G가 만든 것인지, 혹은 실제 데이터 분포 상에 존재하는 것인지 구분해야 하는 D이다. G는 마치 위조 화폐를 만들어 발각되지 않고 사용하려는 위조범과 유사하다. 그리고 D는 위조 화폐를 탐지하려는 경찰과 유사하다. 이 게임은 위조품이 진품과 구별될 수 없을때까지 양 팀의 방법을 개선하도록 유도된다.
이 framework에서는 다양한 종류의 모델과 최적과 알고리즘을 적용시켜 여러 특정 학습 알고리즘을 만들어 볼 수 있다. 이 논문에서는 생성 모델 G는 다층 퍼셉트론에 랜덤 노이즈를 통과시켜 샘플을 생성하는 특수한 경우와 판별 모델 D도 다층 퍼셉트론을 통과시켜 이를 구분하는 모습을 볼 수 있다. 저자는 이러한 경우를 adversarial net이라고 부른다. 이 경우에 매우 성공적인 back propagation 및 dropout 알고리즘 만 사용해서 두 모델을 학습시키고 forward propagation만 사용해서 G가 샘플링할 수 있다. 앞에서 말했듯이 여기서는 다른 생성 ai에서 활용되는 markov chain이나 근사 추론을 사용하지 않는다.
Adversarial nets
적대적 모델링 프레임워크는 모델이 multylayer perceptron일 때 직관적으로 사용이 가능하며, G와 D에 대한 목적함수는 다음과 같다.
여기서 실제 데이터 x에 대한 G의 학습을 위해서 input noise variable을 z~p_z(z)로 정의하고 x domain에 대한 data space의 mapping을 G(z; Θ_g)로 표현했다. 여기서 G는 Θ_g를 parameter로 하는 다층 신경망에 의해 표현되는 미분 가능한 함수이다. 그리고 분류기 D는 single scalar를 출력하며, D(x;Θ_d)로 표현되는 다층 신경망이다. D(x)는 x가 생성기보다 실제 데이터에서 유래됐을지에 대한 확률을 의미한다.(실제 데이터라면 1에 가깝고, 아니라면 0에 가까울 것이다.) 즉 위 식은 D는 실제 데이터와 가짜 데이터를 잘 구분할 수 있도록 목적식을 최대화해야 하고, G는 D를 방해하기 위해 전체 목적식을 최소화해야 하는 two-player minimax game을 의미한다.
이 minimax game에 대한 알고리즘은 다음과 같다.
- k번 반복
- random noise sample {z, …}에 대한 이미지 생성
- 실제 데이터 {x}에 대한 샘플
- stochastic gradient를 올리는 방향으로 discriminator update
- random noise sample {z, …}에 대한 이미지 생성
- stochastic gradient를 내리는 방향으로 generator를 update
- end for
Theoretical Results
Experiments
- MNIST, Toronto Face Database(TFD), CIFAR-10에 대해 학습을 진행하였다.
- G는 RELU, sigmoid를 혼합했고, D는 maxout activatio을 사용함.
- D를 학습 시킬때는 dropout을 사용함
- 이론상의 framework에서는 generator의 중간층에 dropout과 noise를 허용하지 않지만, 이 실험에서는 generator net의 맨 하위계층에 input으로 noise를 사용했다고 한다.
- 이 실험에서는 G로 생성된 sample에 Gaussian Parzen window를 맞추고, 해당 분포에 따른 log-likelihood를 알려줌으로써 Pg에 따른 test set data를 추정했다.
- 결과로, G가 생성해낸 sample이 기존의 방법으로 만든 sample들보다 좋다고 할 수는 없지만, 더 나은 생성모델과 경쟁할 수 있으며, adversarial framework의 잠재력을 강조함.
Advantages and disadvantages
장점
- markov chain이 필요없고, gradient를 계산하기 위해 back-propagation만 사용됨
- 학습 중 inference가 필요 없음
- 다양한 함수들이 모델에 접목될 수 잇음
- markov chain을 쓸 때보다 훨씬 선명한 이미지를 얻을 수 있음
단점
- pg(x)가 명시적으로 존재하지 않음
- D와 G가 균형을 잘 막춰 성능이 향상되어야 함.(D가 학습이 되기 전에 G를 먼저 너무 학습시키면 z 데이터를 너무 많이 붕괴시킬 수 있다고 한다.)
Conclusions and future work
- conditional generative model로 발전시킬 수 있다.
- learned approximate inference는 주어진 x를 예측하여 수행될 수 있다.
- parameter를 공유하는 conditilnals model을 학습해서 다른 conditionals model을 근사적으로 모델링할 수 ㅣㅇㅆ다.
- seme-supervised learning, 즉, 레이블이 제한되어 있는 데이터를 사용할 때, classifier의 성능을 향상시킬 수 있다.
- 효율성 개선. G와 D를 조정하는 더 나은 방법 또는 학습하는 동안 sample z에 대한 더 나은 분포를 결정함으로써 학습의 속도를 높일 수 있다.
샘플 코드
GAN for MNIST Tutorial
Colaboratory notebook
colab.research.google.com
참고 자료
https://arxiv.org/abs/1406.2661
https://tobigs.gitbook.io/tobigs/deep-learning/computer-vision/gan-generative-adversarial-network
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] Vision Transformer[2] 구현 (0) | 2023.08.02 |
|---|---|
| [논문리뷰] Vision Transformer[1] 논문 정리 (0) | 2023.08.01 |
| [논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.07.04 |
| [논문리뷰] You only look once(YOLO) (0) | 2023.06.29 |
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |