
-
Abstract
-
1. Introduction
-
2. Related work
-
2.1. Transformer
-
2.2. attention을 이미지에 적용
-
2.3. CNN + self-attention
-
2.4. larger dataset을 학습해서 성능 향상한 모델들
-
3. Method
-
3.1. Vision Transformer
-
3.2. Fintuning & High resolution
-
4. Experiments
-
4.1. Setup
-
4.2. Comparison to State Of The Art
-
4.3. Pre-Training Data Requirements
-
4.4. Scaling Study
-
4.5. Inspecting Vision Transformer
-
4.6. Self-Supervision
-
5. Concolusion
-
참고자료)
Abstract
Transformer architecture가 나오면서, NLP에서 많은 task들이 영향을 받았다. 하지만, computer vision 영역에 영향은 아직 제한적이다. 아직 cv에서 attention은 convolutional network과 함께 사용하거나, 전체 구조는 그대로 놔둔채 convolutional network의 일부분만 대체할 뿐이다. 저자는 이번에 CNN의 의존성에서 벗어나 순수 transformer를 활용해 image를 patch로 나눠서 sequence 형태로 만든 다음 image classification task를 수행하고자 한다.
1. Introduction
self-attention-based architecture인 transformer에 대한 소개와 computer vision에서의 현재까지의 연구 내용들에 대해서 간략하게 설명하고 있다. 저자는 아직 classic ResNet like architecture들이 SOTA를 찍고 있다고 한다.
NLP에서 transformer가 괄목할만한 성공을 보여준 것에 영감을 받아서 저자는 표준 transformer를 image에 몇가지 변화만 주면서, 바로 적용시킬 수 있는 실험을 해본다. 먼저, 이미지를 작게 쪼개서 patch 단위로 나누고, 이 patch들을 transformer에 input으로 sequencital하게 전달하도록 한다. 여기서 image patch는 NLP에서 token과 비슷한 개념이라고 생각하면 될 것 같다. 저자는 지도 학습으로 image classification을 수행했다.
mid-size의 데이터셋(ImageNet과 같은)을 강력한 regularization 없이 학습시키면, 모델은 비슷한 사이즈의 ResNet보다 약간 accuracy가 낮은 결과를 나타낸다. 언뜻 보기에 낙담할 수 있는 결과라고 생각할 수 있다. 왜냐하면, Transformer는 CNN이 본래 갖고 있는 특성인 translation equivariance와 locality와 같은 inductive bias가 부족하기 때문이다. 따라서 부족한 양의 데이터로 학습이 된다면 일반화가 잘 되지 않는다.
하지만, 14M에서 300M만큼의 크기의 데이터셋을 갖고 학습한다면, inductive bias를 극복할 수 있다고 한다.
2. Related work
2.1. Transformer
2017년도에 나왔으며 NLP task에서 transformer를 활용한 모델들이 SOTA를 찍고 있다. 그러다가 큰 데이터셋에서 pretrain된 다음, task별로 fine-tuning하는 방법을 사용하기 시작했는데, 대표적인 예가 BERT, GPT
- BERT는 denoising self-supervised pre-training task를 사용
- GPT 계열은 pre-training task로서 language modeling을 사용
- 라고 논문에 나오긴 했는데, BERT와 GPT의 차이는 encoder를 쓰는지(BERT)와 decoder를 쓰는지(GPT)인 걸로 알고 있음
2.2. attention을 이미지에 적용
attention을 단순히 이미지에 활용하는 것은 픽셀이 다른 픽셀에 attention을 수행하는 것을 생각할 수 있다. 그렇게 되면, 픽셀 당 계산해야 하는 수가 너무 커지므로, 실제 입력 크기로 확장할 수 없게 된다. 따라서 이미지와 관련해서 Transformer를 적용하기 위해 과거에 몇가지 비슷한 실험이 시도됨.
2.2.1. 관련 실험들
- Image Transformer: 전역이 아닌 각 쿼리 픽셀에 대해 로컬한 이웃에만 self-attention을 수행.
- local multi head dot-product self-attention block은 convolution block을 완전히 대체한 실험
- Sparse Transformer라는 기술은 이미지에 적용할 수 있도록 global self-attention에 대한 확장 가능한 근사를 사용함.
- Attention을 확장하는 또 다른 방법으로 다양한 크기의 블록에 적용하는 방법을 제안한 실험
이러한 attention architecture를 특수하게 변경하는 방법 중 다수는 컴퓨터 비전 작업에서 유망한 결과를 보여주지만 하드웨어 가속기에서 효율적으로 구현하려면 복잡한 엔지니어링이 필요함
이 논문과 가장 관련이 있는 모델은 Cordonnier가 쓴 모델(On the Relationship between Self-Attention and Convolutional Layers), 입력 이미지에서 크기 2x2의 패치를 추출, 그 위에 full self-attention을 적용함. 하지만, 이 논문은 CNN을 활용한 이미지 task보다 성능이 낫다는 걸 보여주지 못함. ViT 더 나아가 대규모 pretrain을 통한 vanilla transformer를 최신 CNN과 경쟁할 수 있도록(혹은 그 이상) 만든다는 것을 보여줄 수 있다. 또한 위의 논문은 2x2픽셀의 작은 patch size를 사용해 모델을 작은 해상도 이미지에만 적용할 수 있지만, ViT는 중간 해상도 이미지도 처리할 수 있음
2.3. CNN + self-attention
CNN과 self-attention의 형태를 결합하는데 여러 관심들이 있었음. 이미지 분류를 위해 feature map을 보강하거나(Bello, 2019), self-attention을 사용해 CNN의 출력을 추가로 처리. 객체 탐지(Hu, 2018; Carion, 2020), 비디오 처리(Wang, 2018,…), 이미지 분류 (Wu et al., 2020), unsupervised 물체 탐지(Locatello et al., 2020), or 통합된 text-vision tasks(Chen et al., 2020c; Lu et al., 2019; Li et al., 2019).
또 다른 관련 최신 모델은 이미지 해상도와 color space을 줄인 후 이미지 픽셀에 Transformer를 적용하는 image GPT(iGPT, 2020)이다. 이 모델은 생성 모델로서 unsupervised로 훈련되며 결과 representation은 분류 성능을 위해 fine-tuning되거나 linear하게 probe되어 ImageNet에서 최대 72%의 정확도를 달성.
2.4. larger dataset을 학습해서 성능 향상한 모델들
아래 논문들은 표준 image dataset이 아닌, 더 큰 dataset을 학습해서 성능 향상을 기록한 모델들이다.
추가 데이터 소스를 사용하면 benchmark에서 SOTA를 얻을 수 있는 실험들도 있었음(Mahajan et al., 2018; Touvron et al., 2019; Xie et al., 2020). Moreover, Sun et al. (2017))
또한 Sun(2017)은 CNN 성능이 데이터 셋 크기에 따라 어떻게 확장되는지 연구하고 Djolonga(2020)은 ImageNet-21k 및 JFT-300M과 같은 대규모 데이터 셋에서 CNN transfer learning의 경험적 탐색을 수행.
저자는 이러한 larger 데이터 셋들에도 초점을 맞추지만 위에서 사용된 ResNet 기반 모델 대신 이 논문은 Transformer를 학습한다.
3. Method
기존의 표준 transformer 구조를 최대한 따라가려고 함.
3.1. Vision Transformer
transformer는 1차원의 sequence가 입력되지만, 2D 이미지를 다루기 위해서 이미지를 $ x \in R^{H*W*C} $ 에서 $x_p \in R^{N * (P^2 * C)}$ 로 reshape한다.
여기서 H, W는 resolution, C는 Channel, (P * P)는 이미지 patch 해상도(크기), $N = HW/P^2$은 P로 나눈 이미지의 갯수이다.
transformer는 모든 레이어에서 크기 D만큼의 constant latent vector를 사용한다. 그래서 저자는 patch를 flatten시키고, 학습 가능한 linear projection을 이용해 D dimension으로 mapping한다.
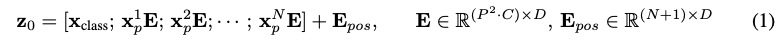
이러한 projection output을 여기서는 patch embedding이라고 부를 예정이다.
BERT의 [class] token과 유사하게, embedded patch sequence($z^0_0 = x_class$)의 앞에 학습 가능한 embedding을 추가한다. transformer encoder($z^0_L$)의 output에서 이것의 상태는 이미지 representation y의 역할을 한다. pre training과 fine-tuning 모두에서, classification head는 $z^0_L$에 attatch 되었다. classification head는 MLP에 의해 수행되었음(1 hidden layer at pre training time, fine tuning time에서는 single linear layer). 이부분은 잘 모르겠다
위치 정보를 알기 위해서, patch embedding에 positional embedding이 추가되었다. 2D-aware position embedding을 사용할 때 별다른 성능 향상을 관찰하지 못했기 때문에, standard learnable 1D position embedding을 사용했다. embedding vector의 encoder에 input으로 들어간다.
Transformer encdoer는 multiheaded self attention의 alternating layer와 MLP block으로 구성되어 있음. Layer_norm은 모든 블럭 전에 적용이 되어 있고, residual connection은 block 뒤에 적용되어 있음.
MLP는 2 layer(with a GELU non-linearity)을 포함한다.
참고) GELU
dropout + zoneout + ReLU를 합친 수식이라고 한다. 아래와 같이 여러 형태로 나타날 수 있다고 한다.
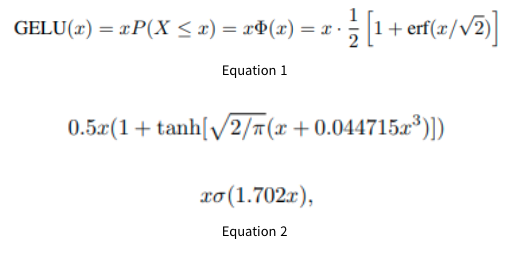
자세한 개념은 나중에 정리하도록 하자..(너무 어려워잉)
참고)
https://keepgoingrunner.tistory.com/91
https://velog.io/@tajan_boy/Computer-Vision-GELU
Inductive bias
ViT가 CNN보다 image-specific inductive bias를 덜 갖고 있다. CNN에서는 locality, 2차원 neighborhood structure, translation equivariance가 전체 모델을 통틀어서 각 레이어에 적용된다. ViT에서는 MLP layer만 local이고 trainslationally equivariant(동등)하며, self-attention layer는 global하다. 2차원 이웃 구조는 매우 드물게 사용된다. 모델 시작시 이미지를 patch로 자르고 fine-tuning 시간에 다른 해상도의 이미지에 대한 위치 임베딩을 조정한다. 그 외에 초기화 시 position embedding은 patch의 2D 위치에 대한 정보를 전달하지 않으며 patch 간의 모든 공간 관계를 처음부터 학습해야 한다.
참고) Inductive bias란?
출처 - https://kmhana.tistory.com/27
https://robot-vision-develop-story.tistory.com/29
inductive bias는 학습 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미한다.(wikipedia) 먼저, 가정(assumption)에 대해서 짚고 넘어가야 한다. 이 '가정'이라는 것이 강력하다면, 가정이 맞았을 때 성능은 매우 높아지지만, 만약에 가정이 틀리다면 예측의 성능은 매우 낮아진다고 한다. 반대로 가정이 약하다면, 가정이 맞았을 때 성능 향상은 미미할 수 있지만, 가정이 틀렸을 때의 성능 하락 또한 약할 수가 있다는 것이다(==robust하다). 따라서 assumption과 robust는 trade-off 관계에 있다고 할 수 있다.
| Assumption | robust |
| 강력 | 낮다 |
| 약함 | 높다 |
이 때, RNN architecture는 설계를 할 때, sequential한 데이터셋끼리 연관이 있을 것이라는 '가정'에 설계되었기 때문에 서로 붙어있는 데이터끼리에서는 성능이 잘 나왔다고 한다(국소적인 부분에서는 성능이 잘 나왔다.) 하지만, input data가 커질 수록 맨 끝에서 맨끝까지의 성능은 잘 안나오게 되었다. 이 때, transformer라는게 나왔는데, attention mechanism과 position embedding을 통해서 transformer는 global한 영역을 모두 커버할 수 있게 된 것이다.
자 이제, transformer를 이미지 영역으로 끌고 와 보려고 하는데, 여기서 CNN 또한 locality라는 '가정'을 통해서 spatial만 문제를 풀 수 있는 능력이 있었다고 한다. 내가 이해하기로는 filter를 통과시키는 것을 상상해보면, filter를 통해서 해당 영역(local)에 대해서 정보를 잘 받아올 수 있다고 '가정'한다는 것을 의미하는 것 같다. 따라서 이것도 강력한 가정이라고는 하는데, 어쨌든, 이러한 강력한 '가정' 때문에 local한 부분과 작은 사진에서는 잘 동작할 수 있지만, global한 영역까지 끌고 가려니 성능 향상이 힘들었다고 한다. 뭐 그래서 이런저런 시도가 있었다고는 한다.
이 때, transformer를 이미지 영역으로 적용시키려고 해보니, attention을 통해서 global한 문제는 풀릴 수 있는데, inductive bias, 추가적인 가정은 부족하다는 것이다. 따라서 Robust하게 동작할 수는 있으나, 성능 문제에 대해서 이렇다할 방안은 없어 보인다. 방법이 하나 있긴 한데, 그것은 바로 데이터를 무지막지하게 넣는 것이다.
(여기서는 내 가설인데) 데이터를 무지막지하게 때려 박으면, 이런저런 다양한 이미지들이 많이 들어갈 건데, '가정'이 강한 모델은 robust하지 않기 때문에, 그런 다양성이 대해서 취약할 것이고, 반면에 '가정'이 약하다 보니 융통성 있게 받아들일 수 있게 되는 것 같다.
hybrid Architecture
raw image patch의 대안으로 input sequence는 CNN의 feature map에서 형성될 수 있다. 이 hybrid model에서 patch embedding projection인 E(식 1)은 CNN feature map에서 추출된 patch에 적용된다. 특수한 경우로 patch의 space size는 1x1일 수 있다. 즉, 단순히 feature map의 spatial dimension을 flatten하고 transformer dimension에 projection해서 input sequence를 얻는다. classification input embedding 및 position embedding은 설명한대로 추가된다.
--> 요약: image patch를 추출할 때, CNN의 feature map을 활용해서 진행하면, performance gain을 얻을 수가 있다.
3.2. Fintuning & High resolution
일반적으로 대규모 데이터 셋에서 ViT를 pretraining하고 (더 작은) downstream task로 fine-tuning한다. 이를 위해 pretrained prediction head를 제거하고 0으로 초기화된 D x K feed-forward layer를 연결한다. 여기서 K는 down-stream class의 갯수이다.
pre-training보다 더 높은 resolution에서 fine-tuning하는 것이 성능에 도움이 된다. 더 높은 해상도의 이미지를 넣고, patch size를 동일하게 유지하면 sequence의 길이가 더 커진다. Vision Transfoormer는 arbitrary(임의의) sequence 길이(메모리 제약 상태까지)를 처리할 수 있지만, pre-trained position embedding은 더 이상 의미가 없을 수 있다. 따라서 원본 이미지의 위치에 따라서 pre-trained position embedding의 2D interpolation을 수행한다. 이 해상도 조정 및 patch extraction은 이미지의 2D 구조에 대한 inductive bias가 수동으로 Vision Transformer에 주입되는 유일한 포인트이다.
4. Experiments
ResNet, ViT, hybrid의 학습 capability를 비교함. 각 모델에 대해서 데이터의 필요도를 알기 위해서 다양한 사이즈의 데이터셋으로 pretraining을 진행했으며, 다양한 benchmark task에서 평가를 진행함. model을 pre-training하는데 computational cost를 고려함에 있어서, ViT는 더 낮은 pre-training cost로 대부분의 recognition benchmark에서 SOTA를 찍었다. 그리고 ViT를 이용해서 self-supervision도 연구함.
4.1. Setup
Datasets
model의 scalability를 확인하기 위해, ILSVRC-20122 ImageNet dataset with 1k classes and 1.3 images(앞으로 이 데이터셋을 ImageNet이라고 부를 예정), 21k class 및 14M 이미지가 포함된 상위 집합 ImageNet-21k(Deng et al., 2009), 18k class 및 303M 고해상도 이미지가 있는 JFT(Sun et al., 2017)를 사용함. 이하 생략(테스트에는 ~~한 데이터를 사용했다. 등등)
Model Variants
BERT에서 사용된 방식의 configuration으로 ViT model을 다양화함. 'Base'와 'Large' model은 BERT에서 쓰는 방식과 동일한데, 'Huge'모델이라고 더 큰 모델을 추가함. 자세한건 표로 나타냄
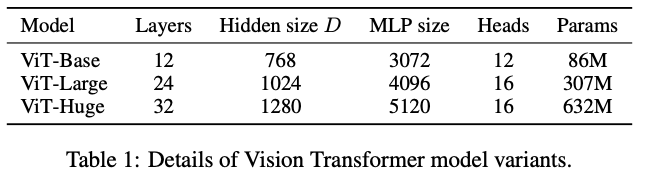
Training & Fine-tuning: beta_1 = 0.9, beta_2 = 0.999 batch_size = 4096 weight decay = 0.1 등등.. 생략
Metrics 생략
4.2. Comparison to State Of The Art
저자들은 먼저 ViT variants 모델들 중 가장 큰 size의 ViT-H/14와 ViT-L/16을 SOTA 성능의 CNN들과 비교함.
첫 비교대상은 대규모의 ResNet으로 supervised transfer learning을 수행시킨 Big Transfer(BiT)모델이고, 두 번째 대상은 Imagenet과 JFT-300M(라벨이 제거된)으로 semi-supervised learning을 이용해 학습시킨 large EfficientNet인, Noisy Student임. 이 때 당시 ImageNet에 대해서는 Noisy Student가 SOTA고, 이외 데이터셋들에 대해서는 BiT-L이 SOTA
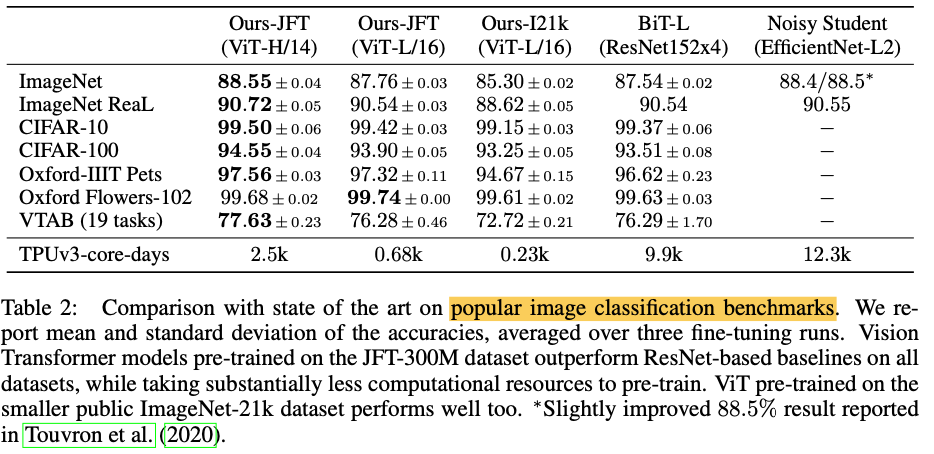
ViT-L/16은 같은 데이터셋을 썼음에도 불구하고, BiT-L의 성능을 능가했다. 그리고 더 큰 모델인 ViT-H/14는 대부분의 dataset에서 SOTA를 기록했고, 게다가 pre-training 시간 또한 BiT-L이나 Noisy Student보다 덜 걸렸다는 점을 주목해볼 수 있겠다.
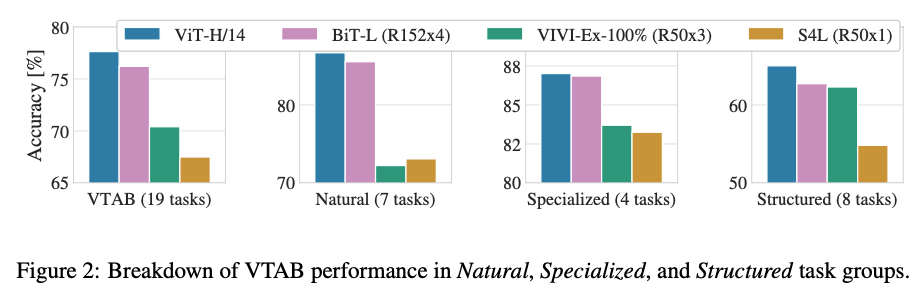
19-task VTAB classification suite를 아래와 같이 3개의 그룹으로 나누어 실험
- Natural - Pets, CIFAR 등과 같은 task
- Specialized - 의료 및 위성 이미지
- Structured - localization과 같이 기하학적 이해가 필요한 task
전체 데이터뿐만 아니라 각 그룹에서도 ViT-H/14가 높은 정확도를 보임
4.3. Pre-Training Data Requirements
Vision Transformer는 대규모 JFT-300M 데이터 세트에서 사전 훈련되었을 때 성능이 좋은 것을 확인할 수 있었는데, 그렇다면, dataset size가 ViT에게 얼마나 중요할까?
먼저, ImageNet, ImageNet-21k, JFT-300M으로 pretrain을 했고, 더 작은 데이터셋에서 퍼포먼스를 향상시키기 위해 기본적인 regularization(weight decay, dropout, label smoothing)을 진행했다. 다음은 ImageNet에서 fine-tuning했을 때 결과이다.
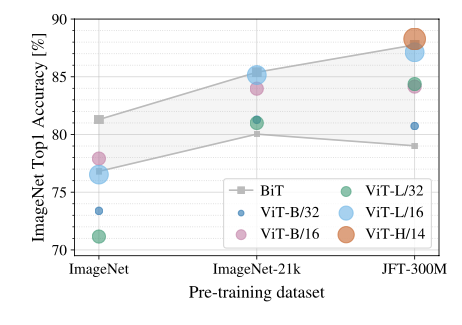
작은 데이터셋으로 pretraining을 진행하면 BiT보다 못한 성능을 보여준다. 심지어 size가 큰 ViT-L/16인데도, ViT-B/16 보다 성능이 못한 것을 보여준다. imageNet-21k를 쓸때는 BiT와 비슷한 성능을 보이고, JFT-300M을 썼을 때 비로소 BiT보다 높은 성능을 보여준다.
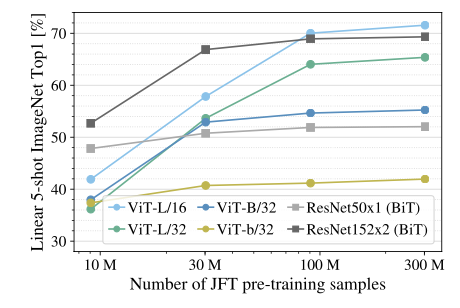
JFT-300M dataset에서 9M, 30M, 90M의 random subset으로 실험한 자료. 작은 데이터를 사용할 수록 ResNet보다 ViT가 overfit하는 모습을 볼 수 있다고 한다.
4.4. Scaling Study
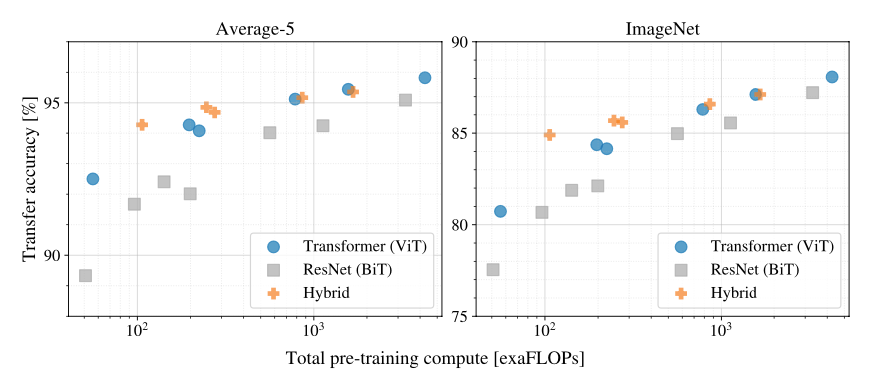
transfer performance vs total pre-training compute
몇 가지 패턴을 관찰할 수 있다.
- Vision Transformers는 성능/컴퓨팅 트레이드 오프에서 ResNets를 압도한다. ViT는 동일한 성능을 달성하기 위해 약 2 - 4배 더 적은 컴퓨팅을 사용한다(평균 5개 데이터 세트 이상).
- hybrid는 small computational budget에서 ViT를 약간 능가하지만 더 큰 모델에서는 그 차이가 사라진다.
- Vision Transformers는 시도한 범위 내에서 포화되지 않는 것으로 나타나므로, 향후에 scaling할 때 가능성을 열어둘 수 있다.
4.5. Inspecting Vision Transformer

요약: 실제로 class와 관련된 영역에 'attention'한다는 것을 보여주는 자료
4.6. Self-Supervision
transformer가 유명해졌던 거는 scalability도 있겠지만, self-supervise learning 때문이라고 저자는 말한다. 그래서 저자도 BERT에서 썼던 것처럼 'masked patch prediction'을 시도해 보았다. self-supervised pre-training 이후, ViT-B/16 model은 ImageNet에서 79.9%를 기록했는데, 이는 scratch보다는 2%가 높았지만, supervised pre-training보다는 4%가 낮았다고 한다.
5. Concolusion
이미지 인식에 트랜스포머를 직접 적용하는 방법을 살펴보았다. 이미지를 일련의 patch로 해석하고, 이것을 NLP에서 사용되는 표준 Transformer 인코더로 처리한다. 이 단순하지만 확장 가능한 전략은 대규모 데이터 세트에 대한 pre-training과 결합될 때 놀라울 정도로 잘 작동한다. 따라서 Vision Transformer는 많은 이미지 분류 데이터 세트에서 최신 기술 이상의 성능을 보이면서도, 상대적으로 pre-training 비용이 저렴한 장점이 있다.
이러한 결과는 고무적이지만 많은 과제가 남아 있다.
- 하나는 감지 및 분할과 같은 다른 컴퓨터 비전 작업에 ViT를 적용하는 것.
- 또 다른 과제는 self-supervised pre-training method이다.
마지막으로 ViT의 추가 scaling은 성능 향상으로 이어질 가능성이 높다고 한다
참고자료)
Vision Transformer: https://arxiv.org/abs/2010.11929
transforemer wikidocs: https://wikidocs.net/31379
ViT 관련 정리 블로그
inductive bias
https://robot-vision-develop-story.tistory.com/29
GELU
https://keepgoingrunner.tistory.com/91
https://velog.io/@tajan_boy/Computer-Vision-GELU
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] Vision Transformer[2] 구현 (0) | 2023.08.02 |
|---|---|
| [논문리뷰] generative adversarial networks(GAN) (0) | 2023.07.13 |
| [논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.07.04 |
| [논문리뷰] You only look once(YOLO) (0) | 2023.06.29 |
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |
Abstract
Transformer architecture가 나오면서, NLP에서 많은 task들이 영향을 받았다. 하지만, computer vision 영역에 영향은 아직 제한적이다. 아직 cv에서 attention은 convolutional network과 함께 사용하거나, 전체 구조는 그대로 놔둔채 convolutional network의 일부분만 대체할 뿐이다. 저자는 이번에 CNN의 의존성에서 벗어나 순수 transformer를 활용해 image를 patch로 나눠서 sequence 형태로 만든 다음 image classification task를 수행하고자 한다.
1. Introduction
self-attention-based architecture인 transformer에 대한 소개와 computer vision에서의 현재까지의 연구 내용들에 대해서 간략하게 설명하고 있다. 저자는 아직 classic ResNet like architecture들이 SOTA를 찍고 있다고 한다.
NLP에서 transformer가 괄목할만한 성공을 보여준 것에 영감을 받아서 저자는 표준 transformer를 image에 몇가지 변화만 주면서, 바로 적용시킬 수 있는 실험을 해본다. 먼저, 이미지를 작게 쪼개서 patch 단위로 나누고, 이 patch들을 transformer에 input으로 sequencital하게 전달하도록 한다. 여기서 image patch는 NLP에서 token과 비슷한 개념이라고 생각하면 될 것 같다. 저자는 지도 학습으로 image classification을 수행했다.
mid-size의 데이터셋(ImageNet과 같은)을 강력한 regularization 없이 학습시키면, 모델은 비슷한 사이즈의 ResNet보다 약간 accuracy가 낮은 결과를 나타낸다. 언뜻 보기에 낙담할 수 있는 결과라고 생각할 수 있다. 왜냐하면, Transformer는 CNN이 본래 갖고 있는 특성인 translation equivariance와 locality와 같은 inductive bias가 부족하기 때문이다. 따라서 부족한 양의 데이터로 학습이 된다면 일반화가 잘 되지 않는다.
하지만, 14M에서 300M만큼의 크기의 데이터셋을 갖고 학습한다면, inductive bias를 극복할 수 있다고 한다.
2. Related work
2.1. Transformer
2017년도에 나왔으며 NLP task에서 transformer를 활용한 모델들이 SOTA를 찍고 있다. 그러다가 큰 데이터셋에서 pretrain된 다음, task별로 fine-tuning하는 방법을 사용하기 시작했는데, 대표적인 예가 BERT, GPT
- BERT는 denoising self-supervised pre-training task를 사용
- GPT 계열은 pre-training task로서 language modeling을 사용
- 라고 논문에 나오긴 했는데, BERT와 GPT의 차이는 encoder를 쓰는지(BERT)와 decoder를 쓰는지(GPT)인 걸로 알고 있음
2.2. attention을 이미지에 적용
attention을 단순히 이미지에 활용하는 것은 픽셀이 다른 픽셀에 attention을 수행하는 것을 생각할 수 있다. 그렇게 되면, 픽셀 당 계산해야 하는 수가 너무 커지므로, 실제 입력 크기로 확장할 수 없게 된다. 따라서 이미지와 관련해서 Transformer를 적용하기 위해 과거에 몇가지 비슷한 실험이 시도됨.
2.2.1. 관련 실험들
- Image Transformer: 전역이 아닌 각 쿼리 픽셀에 대해 로컬한 이웃에만 self-attention을 수행.
- local multi head dot-product self-attention block은 convolution block을 완전히 대체한 실험
- Sparse Transformer라는 기술은 이미지에 적용할 수 있도록 global self-attention에 대한 확장 가능한 근사를 사용함.
- Attention을 확장하는 또 다른 방법으로 다양한 크기의 블록에 적용하는 방법을 제안한 실험
이러한 attention architecture를 특수하게 변경하는 방법 중 다수는 컴퓨터 비전 작업에서 유망한 결과를 보여주지만 하드웨어 가속기에서 효율적으로 구현하려면 복잡한 엔지니어링이 필요함
이 논문과 가장 관련이 있는 모델은 Cordonnier가 쓴 모델(On the Relationship between Self-Attention and Convolutional Layers), 입력 이미지에서 크기 2x2의 패치를 추출, 그 위에 full self-attention을 적용함. 하지만, 이 논문은 CNN을 활용한 이미지 task보다 성능이 낫다는 걸 보여주지 못함. ViT 더 나아가 대규모 pretrain을 통한 vanilla transformer를 최신 CNN과 경쟁할 수 있도록(혹은 그 이상) 만든다는 것을 보여줄 수 있다. 또한 위의 논문은 2x2픽셀의 작은 patch size를 사용해 모델을 작은 해상도 이미지에만 적용할 수 있지만, ViT는 중간 해상도 이미지도 처리할 수 있음
2.3. CNN + self-attention
CNN과 self-attention의 형태를 결합하는데 여러 관심들이 있었음. 이미지 분류를 위해 feature map을 보강하거나(Bello, 2019), self-attention을 사용해 CNN의 출력을 추가로 처리. 객체 탐지(Hu, 2018; Carion, 2020), 비디오 처리(Wang, 2018,…), 이미지 분류 (Wu et al., 2020), unsupervised 물체 탐지(Locatello et al., 2020), or 통합된 text-vision tasks(Chen et al., 2020c; Lu et al., 2019; Li et al., 2019).
또 다른 관련 최신 모델은 이미지 해상도와 color space을 줄인 후 이미지 픽셀에 Transformer를 적용하는 image GPT(iGPT, 2020)이다. 이 모델은 생성 모델로서 unsupervised로 훈련되며 결과 representation은 분류 성능을 위해 fine-tuning되거나 linear하게 probe되어 ImageNet에서 최대 72%의 정확도를 달성.
2.4. larger dataset을 학습해서 성능 향상한 모델들
아래 논문들은 표준 image dataset이 아닌, 더 큰 dataset을 학습해서 성능 향상을 기록한 모델들이다.
추가 데이터 소스를 사용하면 benchmark에서 SOTA를 얻을 수 있는 실험들도 있었음(Mahajan et al., 2018; Touvron et al., 2019; Xie et al., 2020). Moreover, Sun et al. (2017))
또한 Sun(2017)은 CNN 성능이 데이터 셋 크기에 따라 어떻게 확장되는지 연구하고 Djolonga(2020)은 ImageNet-21k 및 JFT-300M과 같은 대규모 데이터 셋에서 CNN transfer learning의 경험적 탐색을 수행.
저자는 이러한 larger 데이터 셋들에도 초점을 맞추지만 위에서 사용된 ResNet 기반 모델 대신 이 논문은 Transformer를 학습한다.
3. Method
기존의 표준 transformer 구조를 최대한 따라가려고 함.
3.1. Vision Transformer
transformer는 1차원의 sequence가 입력되지만, 2D 이미지를 다루기 위해서 이미지를 $ x \in R^{H*W*C} $ 에서 $x_p \in R^{N * (P^2 * C)}$ 로 reshape한다.
여기서 H, W는 resolution, C는 Channel, (P * P)는 이미지 patch 해상도(크기), $N = HW/P^2$은 P로 나눈 이미지의 갯수이다.
transformer는 모든 레이어에서 크기 D만큼의 constant latent vector를 사용한다. 그래서 저자는 patch를 flatten시키고, 학습 가능한 linear projection을 이용해 D dimension으로 mapping한다.
이러한 projection output을 여기서는 patch embedding이라고 부를 예정이다.
BERT의 [class] token과 유사하게, embedded patch sequence($z^0_0 = x_class$)의 앞에 학습 가능한 embedding을 추가한다. transformer encoder($z^0_L$)의 output에서 이것의 상태는 이미지 representation y의 역할을 한다. pre training과 fine-tuning 모두에서, classification head는 $z^0_L$에 attatch 되었다. classification head는 MLP에 의해 수행되었음(1 hidden layer at pre training time, fine tuning time에서는 single linear layer). 이부분은 잘 모르겠다
위치 정보를 알기 위해서, patch embedding에 positional embedding이 추가되었다. 2D-aware position embedding을 사용할 때 별다른 성능 향상을 관찰하지 못했기 때문에, standard learnable 1D position embedding을 사용했다. embedding vector의 encoder에 input으로 들어간다.
Transformer encdoer는 multiheaded self attention의 alternating layer와 MLP block으로 구성되어 있음. Layer_norm은 모든 블럭 전에 적용이 되어 있고, residual connection은 block 뒤에 적용되어 있음.
MLP는 2 layer(with a GELU non-linearity)을 포함한다.
참고) GELU
dropout + zoneout + ReLU를 합친 수식이라고 한다. 아래와 같이 여러 형태로 나타날 수 있다고 한다.
자세한 개념은 나중에 정리하도록 하자..(너무 어려워잉)
참고)
https://keepgoingrunner.tistory.com/91
https://velog.io/@tajan_boy/Computer-Vision-GELU
Inductive bias
ViT가 CNN보다 image-specific inductive bias를 덜 갖고 있다. CNN에서는 locality, 2차원 neighborhood structure, translation equivariance가 전체 모델을 통틀어서 각 레이어에 적용된다. ViT에서는 MLP layer만 local이고 trainslationally equivariant(동등)하며, self-attention layer는 global하다. 2차원 이웃 구조는 매우 드물게 사용된다. 모델 시작시 이미지를 patch로 자르고 fine-tuning 시간에 다른 해상도의 이미지에 대한 위치 임베딩을 조정한다. 그 외에 초기화 시 position embedding은 patch의 2D 위치에 대한 정보를 전달하지 않으며 patch 간의 모든 공간 관계를 처음부터 학습해야 한다.
참고) Inductive bias란?
출처 - https://kmhana.tistory.com/27
https://robot-vision-develop-story.tistory.com/29
inductive bias는 학습 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미한다.(wikipedia) 먼저, 가정(assumption)에 대해서 짚고 넘어가야 한다. 이 '가정'이라는 것이 강력하다면, 가정이 맞았을 때 성능은 매우 높아지지만, 만약에 가정이 틀리다면 예측의 성능은 매우 낮아진다고 한다. 반대로 가정이 약하다면, 가정이 맞았을 때 성능 향상은 미미할 수 있지만, 가정이 틀렸을 때의 성능 하락 또한 약할 수가 있다는 것이다(==robust하다). 따라서 assumption과 robust는 trade-off 관계에 있다고 할 수 있다.
| Assumption | robust |
| 강력 | 낮다 |
| 약함 | 높다 |
이 때, RNN architecture는 설계를 할 때, sequential한 데이터셋끼리 연관이 있을 것이라는 '가정'에 설계되었기 때문에 서로 붙어있는 데이터끼리에서는 성능이 잘 나왔다고 한다(국소적인 부분에서는 성능이 잘 나왔다.) 하지만, input data가 커질 수록 맨 끝에서 맨끝까지의 성능은 잘 안나오게 되었다. 이 때, transformer라는게 나왔는데, attention mechanism과 position embedding을 통해서 transformer는 global한 영역을 모두 커버할 수 있게 된 것이다.
자 이제, transformer를 이미지 영역으로 끌고 와 보려고 하는데, 여기서 CNN 또한 locality라는 '가정'을 통해서 spatial만 문제를 풀 수 있는 능력이 있었다고 한다. 내가 이해하기로는 filter를 통과시키는 것을 상상해보면, filter를 통해서 해당 영역(local)에 대해서 정보를 잘 받아올 수 있다고 '가정'한다는 것을 의미하는 것 같다. 따라서 이것도 강력한 가정이라고는 하는데, 어쨌든, 이러한 강력한 '가정' 때문에 local한 부분과 작은 사진에서는 잘 동작할 수 있지만, global한 영역까지 끌고 가려니 성능 향상이 힘들었다고 한다. 뭐 그래서 이런저런 시도가 있었다고는 한다.
이 때, transformer를 이미지 영역으로 적용시키려고 해보니, attention을 통해서 global한 문제는 풀릴 수 있는데, inductive bias, 추가적인 가정은 부족하다는 것이다. 따라서 Robust하게 동작할 수는 있으나, 성능 문제에 대해서 이렇다할 방안은 없어 보인다. 방법이 하나 있긴 한데, 그것은 바로 데이터를 무지막지하게 넣는 것이다.
(여기서는 내 가설인데) 데이터를 무지막지하게 때려 박으면, 이런저런 다양한 이미지들이 많이 들어갈 건데, '가정'이 강한 모델은 robust하지 않기 때문에, 그런 다양성이 대해서 취약할 것이고, 반면에 '가정'이 약하다 보니 융통성 있게 받아들일 수 있게 되는 것 같다.
hybrid Architecture
raw image patch의 대안으로 input sequence는 CNN의 feature map에서 형성될 수 있다. 이 hybrid model에서 patch embedding projection인 E(식 1)은 CNN feature map에서 추출된 patch에 적용된다. 특수한 경우로 patch의 space size는 1x1일 수 있다. 즉, 단순히 feature map의 spatial dimension을 flatten하고 transformer dimension에 projection해서 input sequence를 얻는다. classification input embedding 및 position embedding은 설명한대로 추가된다.
--> 요약: image patch를 추출할 때, CNN의 feature map을 활용해서 진행하면, performance gain을 얻을 수가 있다.
3.2. Fintuning & High resolution
일반적으로 대규모 데이터 셋에서 ViT를 pretraining하고 (더 작은) downstream task로 fine-tuning한다. 이를 위해 pretrained prediction head를 제거하고 0으로 초기화된 D x K feed-forward layer를 연결한다. 여기서 K는 down-stream class의 갯수이다.
pre-training보다 더 높은 resolution에서 fine-tuning하는 것이 성능에 도움이 된다. 더 높은 해상도의 이미지를 넣고, patch size를 동일하게 유지하면 sequence의 길이가 더 커진다. Vision Transfoormer는 arbitrary(임의의) sequence 길이(메모리 제약 상태까지)를 처리할 수 있지만, pre-trained position embedding은 더 이상 의미가 없을 수 있다. 따라서 원본 이미지의 위치에 따라서 pre-trained position embedding의 2D interpolation을 수행한다. 이 해상도 조정 및 patch extraction은 이미지의 2D 구조에 대한 inductive bias가 수동으로 Vision Transformer에 주입되는 유일한 포인트이다.
4. Experiments
ResNet, ViT, hybrid의 학습 capability를 비교함. 각 모델에 대해서 데이터의 필요도를 알기 위해서 다양한 사이즈의 데이터셋으로 pretraining을 진행했으며, 다양한 benchmark task에서 평가를 진행함. model을 pre-training하는데 computational cost를 고려함에 있어서, ViT는 더 낮은 pre-training cost로 대부분의 recognition benchmark에서 SOTA를 찍었다. 그리고 ViT를 이용해서 self-supervision도 연구함.
4.1. Setup
Datasets
model의 scalability를 확인하기 위해, ILSVRC-20122 ImageNet dataset with 1k classes and 1.3 images(앞으로 이 데이터셋을 ImageNet이라고 부를 예정), 21k class 및 14M 이미지가 포함된 상위 집합 ImageNet-21k(Deng et al., 2009), 18k class 및 303M 고해상도 이미지가 있는 JFT(Sun et al., 2017)를 사용함. 이하 생략(테스트에는 ~~한 데이터를 사용했다. 등등)
Model Variants
BERT에서 사용된 방식의 configuration으로 ViT model을 다양화함. 'Base'와 'Large' model은 BERT에서 쓰는 방식과 동일한데, 'Huge'모델이라고 더 큰 모델을 추가함. 자세한건 표로 나타냄
Training & Fine-tuning: beta_1 = 0.9, beta_2 = 0.999 batch_size = 4096 weight decay = 0.1 등등.. 생략
Metrics 생략
4.2. Comparison to State Of The Art
저자들은 먼저 ViT variants 모델들 중 가장 큰 size의 ViT-H/14와 ViT-L/16을 SOTA 성능의 CNN들과 비교함.
첫 비교대상은 대규모의 ResNet으로 supervised transfer learning을 수행시킨 Big Transfer(BiT)모델이고, 두 번째 대상은 Imagenet과 JFT-300M(라벨이 제거된)으로 semi-supervised learning을 이용해 학습시킨 large EfficientNet인, Noisy Student임. 이 때 당시 ImageNet에 대해서는 Noisy Student가 SOTA고, 이외 데이터셋들에 대해서는 BiT-L이 SOTA
ViT-L/16은 같은 데이터셋을 썼음에도 불구하고, BiT-L의 성능을 능가했다. 그리고 더 큰 모델인 ViT-H/14는 대부분의 dataset에서 SOTA를 기록했고, 게다가 pre-training 시간 또한 BiT-L이나 Noisy Student보다 덜 걸렸다는 점을 주목해볼 수 있겠다.
19-task VTAB classification suite를 아래와 같이 3개의 그룹으로 나누어 실험
- Natural - Pets, CIFAR 등과 같은 task
- Specialized - 의료 및 위성 이미지
- Structured - localization과 같이 기하학적 이해가 필요한 task
전체 데이터뿐만 아니라 각 그룹에서도 ViT-H/14가 높은 정확도를 보임
4.3. Pre-Training Data Requirements
Vision Transformer는 대규모 JFT-300M 데이터 세트에서 사전 훈련되었을 때 성능이 좋은 것을 확인할 수 있었는데, 그렇다면, dataset size가 ViT에게 얼마나 중요할까?
먼저, ImageNet, ImageNet-21k, JFT-300M으로 pretrain을 했고, 더 작은 데이터셋에서 퍼포먼스를 향상시키기 위해 기본적인 regularization(weight decay, dropout, label smoothing)을 진행했다. 다음은 ImageNet에서 fine-tuning했을 때 결과이다.
작은 데이터셋으로 pretraining을 진행하면 BiT보다 못한 성능을 보여준다. 심지어 size가 큰 ViT-L/16인데도, ViT-B/16 보다 성능이 못한 것을 보여준다. imageNet-21k를 쓸때는 BiT와 비슷한 성능을 보이고, JFT-300M을 썼을 때 비로소 BiT보다 높은 성능을 보여준다.
JFT-300M dataset에서 9M, 30M, 90M의 random subset으로 실험한 자료. 작은 데이터를 사용할 수록 ResNet보다 ViT가 overfit하는 모습을 볼 수 있다고 한다.
4.4. Scaling Study
transfer performance vs total pre-training compute
몇 가지 패턴을 관찰할 수 있다.
- Vision Transformers는 성능/컴퓨팅 트레이드 오프에서 ResNets를 압도한다. ViT는 동일한 성능을 달성하기 위해 약 2 - 4배 더 적은 컴퓨팅을 사용한다(평균 5개 데이터 세트 이상).
- hybrid는 small computational budget에서 ViT를 약간 능가하지만 더 큰 모델에서는 그 차이가 사라진다.
- Vision Transformers는 시도한 범위 내에서 포화되지 않는 것으로 나타나므로, 향후에 scaling할 때 가능성을 열어둘 수 있다.
4.5. Inspecting Vision Transformer
요약: 실제로 class와 관련된 영역에 'attention'한다는 것을 보여주는 자료
4.6. Self-Supervision
transformer가 유명해졌던 거는 scalability도 있겠지만, self-supervise learning 때문이라고 저자는 말한다. 그래서 저자도 BERT에서 썼던 것처럼 'masked patch prediction'을 시도해 보았다. self-supervised pre-training 이후, ViT-B/16 model은 ImageNet에서 79.9%를 기록했는데, 이는 scratch보다는 2%가 높았지만, supervised pre-training보다는 4%가 낮았다고 한다.
5. Concolusion
이미지 인식에 트랜스포머를 직접 적용하는 방법을 살펴보았다. 이미지를 일련의 patch로 해석하고, 이것을 NLP에서 사용되는 표준 Transformer 인코더로 처리한다. 이 단순하지만 확장 가능한 전략은 대규모 데이터 세트에 대한 pre-training과 결합될 때 놀라울 정도로 잘 작동한다. 따라서 Vision Transformer는 많은 이미지 분류 데이터 세트에서 최신 기술 이상의 성능을 보이면서도, 상대적으로 pre-training 비용이 저렴한 장점이 있다.
이러한 결과는 고무적이지만 많은 과제가 남아 있다.
- 하나는 감지 및 분할과 같은 다른 컴퓨터 비전 작업에 ViT를 적용하는 것.
- 또 다른 과제는 self-supervised pre-training method이다.
마지막으로 ViT의 추가 scaling은 성능 향상으로 이어질 가능성이 높다고 한다
참고자료)
Vision Transformer: https://arxiv.org/abs/2010.11929
transforemer wikidocs: https://wikidocs.net/31379
ViT 관련 정리 블로그
inductive bias
https://robot-vision-develop-story.tistory.com/29
GELU
https://keepgoingrunner.tistory.com/91
https://velog.io/@tajan_boy/Computer-Vision-GELU
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] Vision Transformer[2] 구현 (0) | 2023.08.02 |
|---|---|
| [논문리뷰] generative adversarial networks(GAN) (0) | 2023.07.13 |
| [논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.07.04 |
| [논문리뷰] You only look once(YOLO) (0) | 2023.06.29 |
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |