
본 포스팅은 ViT를 정리해 놓은 github를 스터디하면서 정리하면서 적은 글입니다.
참고) einops
- einops는 flexible, powerful한 tensor operation이다.
- 노트북에서 사용된 functions는 다음과 같다.
- rearrange, reduce, repeat
rearrange
- tensor element를 특정 패턴으로 재정렬
output_tensor = rearrange(input_tensor, 't b c -> b c t')reduce
- tensor의 rearrange와 reduce(차원 축소)를 함께 진행할 수 있음.
# combine rearrangement and reduction
output_tensor = reduce(input_tensor, 'b c (h h2) (w w2) -> b h w c', 'mean', h2=2, w2=2)repeat
- 새로운 axis를 추가하면서, 그 값들을 복사한다.
# copy along a new axis
output_tensor = repeat(input_tensor, 'h w -> h w c', c=3)Configure
!pip install torch
!pip install einopsimport torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary# 테스트용으로 임의의 이미지 tensor를 만든다.
x = torch.randn(8, 3, 224, 224)
x.shapePatch Embedding
먼저 이미지를 patch 단위로 잘라준다.
batch size x channel x height x width로 된 tensor를 batch size x patch 갯수 x patch size로 바꾼다.
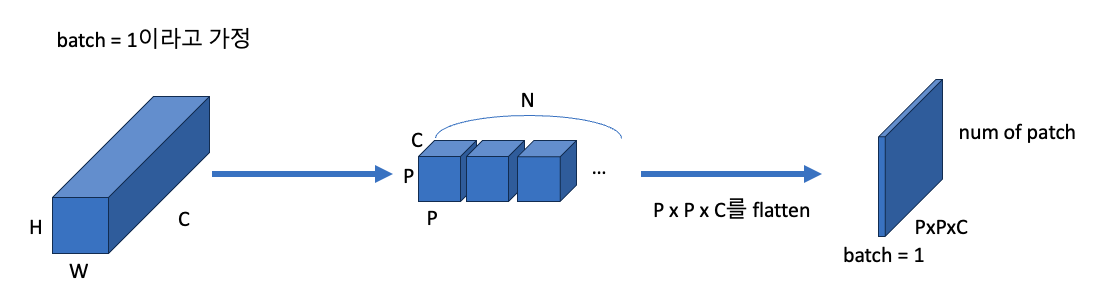
patch_size = 16
# batch_size*C*H*W --> batch_size*patch 갯수*패치사이즈 로 바꾼다.
patches = rearrange(x, 'b c (n1 s1) (n2 s2) -> b (n1 n2) (s1 s2 c)',
s1=patch_size, s2=patch_size)
# 이미지를 patch로 나누고 바로 합칠 수 있다.
print('patch shape:', patches.shape)output
patch shape: torch.Size([8, 196, 768])Patch Embedding Using Convolutional Layer
하지만 실제 ViT에서 patch를 나눌 때는, kernel size와 stride size가 patch size와 동일하게 가져가는 convolutional 2D layer를 이용한 후 flatten 시켜준다. 이렇게 하면 performance gain이 있다고 한다.
patch_size = 16
in_channels = 3
emb_size = 768
projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
# flatten
Rearrange('b e h w -> b (h w) e')
)
print('patch size:', projection(x).shape)shape 변화
# (batch size, embedding size, # of patch, # of patch) --> (8, 196, 768)
# (batch size, embedding size, # of patch(세로), # of patch(가로)) --> (batch_size, # of patch, embedding size)
## embeddig size = patch_size x patch_size x channelPatch Embedding Class
- 위에서 구현한 코드를 바탕으로 PatchEmbedding class를 구현한다
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
super().__init__()
self.patch_size = patch_size
# patch embedding layer
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e')
)
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
PatchEmbedding()(x).shapeoutput
torch.Size([8, 196, 768])CLS token
- 위 코드에서 CLS token을 추가한다.

- 논문에서 각 patch를 token이라고 생각하면 된다고 한다.
- 따라서 그림에서 각 패치를 자연어 처리에서의 token이라고 할 수 있고, 이미지 하나를 자연어 처리에서 문장 단위라고 생각하면 좋을 것 같다.
- 그래서 cls token이 문장 앞에 들어간다.
class PatchEmbedding(nn.Module):
def init(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
super().init()
self.patch_size = patch_size
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e')
)
# cls token
self.cls_token = nn.Parameter(torch.randn(1,1,emb_size))
def forward(self, x: Tensor) -> Tensor:
# batch_size
b, _, _, _ = x.shape
# patch embedding
x = self.projection(x)
# batch_size만큼 복사
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# input 앞에 cls token을 붙입니다.
x = torch.cat([cls_tokens, x], dim=1)
return x
PatchEmbedding()(x).shapeoutput
torch.Size(\[8, 197, 768\])Position Embedding
- patch에 대해서 positional embedding을 진행하는 코드를 추가한다.
- 논문에서 positional embedding의 유무와 그 방식에 관해서 성능 비교 실험을 해봤는데, positional embedding을 하는 것은 성능 향상이 있었지만, 방식에 대해서는 차이점이 없었다.
- position information에 대한 관점
- no positional embedding
- 1-dimensional positional embedding: patch를 하나의 긴 sequence로 보는 방식
- 2-dimentional positional embedding: poisition을 x, y의 2차원으로 보는 관점
- Relative poisitional embeddings: transformer의 q,k,v처럼 하나의 patch 대해서 나머지 patch들의 상대적인 위치를 나타내는 방식
- 1-d, 2d positional embedding에서 세가지 케이스로 나눠서 실험
- positional embedding을 encoder에 feed하기 직전에 추가(기존과 같은 방식)
- 각 layer를 시작할 때 positional embedding에 대해서 학습+add
- 두번째 방식과 같지만, layer별로 position 정보들이 공유됨.
- pixel 단위의 transformer에 비해서 patch 단위로 잘라냄으로써 위치 정보에 대한 중요성이 비교적 작기 때문인 것 같다고 저자는 말햇음.
- 논문 기준으로는 standard learnable 1D position embeddings를 썼다고 함.
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768,
img_size: int = 224):
super().__init__()
self.patch_size = patch_size
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e')
)
# cls token
self.cls_token = nn.Parameter(torch.randn(1,1,emb_size))
# positions shape: (patch 갯수 + 1(cls token), embedding size)
self.positions = nn.Parameter(torch.randn((img_size // patch_size) ** 2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
# batch_size
b, _, _, _ = x.shape
x = self.projection(x)
# batch_size만큼 복사
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# input 앞에 cls token을 붙입니다.
x = torch.cat([cls_tokens, x], dim=1)
# position embedding
x += self.positions
return x
PatchEmbedding()(x).shapeoutput
torch.Size(\[8, 197, 768\])Transformer
- ViT에서 transformer의 encoder 구조만 쓰인다.
MultiHeadAttention
- query와 key를 통해서 element가 나머지 다른 element에게 얼마나 연관이 있는지를 의미하는 attention weight를 얻을 수 있다.
- value에 attention matrix를 곱해서 값을 조정한다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0.):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# q, k, v 생성 layer
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
# attention dropout
self.att_drop = nn.Dropout(dropout)
# 1/sqrt(d_k)
self.scaling = (self.emb_size // num_heads) ** -0.5
# dense layer
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x: Tensor, mask: Tensor = None) -> Tensor:
# q, k, v
# batch_size, patch_num, emb_size(num_head * d_k)
# --> batch_size, head_num, patch_num, d_k
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), 'b n (h d) -> b h n d', h=self.num_heads)
values = rearrange(self.values(x), 'b n (h d) -> b h n d', h=self.num_heads)
# sum up over the last axis
# query vector x key vector
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
# mksoo 수정
# 원문에서는 softmax 바깥에 scaling이 있었는데, transformer는 scaling 후에 softmax를 취하는 것으로 알고 있다.
att = F.softmax(energy * self.scaling, dim=-1)
att = self.att_drop(att)
# sum up over the third axis
# attention weights * value
out = torch.einsum('bhal, bhlv -> bhav', att, values)
# batch_size, head_num, patch_num, d_k
# --> batch_size, patch_num, emb_size
out = rearrange(out, 'b h n d -> b n (h d)')
# dense layer 통과
out = self.projection(out)
return out
patches_embedded = PatchEmbedding()(x)
MultiHeadAttention()(patches_embedded).shapeoutput
torch.Size(\[8, 197, 768\])원문에서는 qkv를 한 번에 계산하는 과정이 있는데, 그건 skip한다.
Residuals
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return xMLP
- 저자가 forward method 작성 안하려고 그냥 이렇게 작성함.
- 저자도 그냥 해봤는데 되길래 이렇게 작성한다고 함.
- 여기서 GELU는 ReLU + zoneout + dropout을 합친 개념이라고 생각하면 된다.(자세한 내용은 skip)
- 요즘 nlp나 cv에서 많이 쓰이는 activation function 인가봄
class FeedForwardBlock(nn.Sequential): def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.): super().__init__( nn.Linear(emb_size, expansion * emb_size), nn.GELU(), nn.Dropout(drop_p), nn.Linear(expansion * emb_size, emb_size), )
TransformerEncoderBlock
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))Classification Head
분류를 위한 마지막 fc-layer
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
# fc layer에 통과시키기 위해 batch를 빼고 싹 flatten
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))ViT
PatchEmbedding, TransformerEncoder, ClassificationHead를 합쳐서 ViT 구성
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)output
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
PatchEmbedding-3 [-1, 197, 768] 0
LayerNorm-4 [-1, 197, 768] 1,536
Linear-5 [-1, 197, 768] 590,592
Linear-6 [-1, 197, 768] 590,592
Linear-7 [-1, 197, 768] 590,592
Dropout-8 [-1, 8, 197, 197] 0
Linear-9 [-1, 197, 768] 590,592
MultiHeadAttention-10 [-1, 197, 768] 0
Dropout-11 [-1, 197, 768] 0
ResidualAdd-12 [-1, 197, 768] 0
LayerNorm-13 [-1, 197, 768] 1,536
Linear-14 [-1, 197, 3072] 2,362,368
GELU-15 [-1, 197, 3072] 0
Dropout-16 [-1, 197, 3072] 0
Linear-17 [-1, 197, 768] 2,360,064
Dropout-18 [-1, 197, 768] 0
ResidualAdd-19 [-1, 197, 768] 0
LayerNorm-20 [-1, 197, 768] 1,536
Linear-21 [-1, 197, 768] 590,592
Linear-22 [-1, 197, 768] 590,592
Linear-23 [-1, 197, 768] 590,592
Dropout-24 [-1, 8, 197, 197] 0
Linear-25 [-1, 197, 768] 590,592
MultiHeadAttention-26 [-1, 197, 768] 0
...중략
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
Input size (MB): 0.57
Forward/backward pass size (MB): 364.33
Params size (MB): 329.65
Estimated Total Size (MB): 694.56
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] Vision Transformer[1] 논문 정리 (0) | 2023.08.01 |
|---|---|
| [논문리뷰] generative adversarial networks(GAN) (0) | 2023.07.13 |
| [논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.07.04 |
| [논문리뷰] You only look once(YOLO) (0) | 2023.06.29 |
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |
본 포스팅은 ViT를 정리해 놓은 github를 스터디하면서 정리하면서 적은 글입니다.
참고) einops
- einops는 flexible, powerful한 tensor operation이다.
- 노트북에서 사용된 functions는 다음과 같다.
- rearrange, reduce, repeat
rearrange
- tensor element를 특정 패턴으로 재정렬
output_tensor = rearrange(input_tensor, 't b c -> b c t')reduce
- tensor의 rearrange와 reduce(차원 축소)를 함께 진행할 수 있음.
# combine rearrangement and reduction
output_tensor = reduce(input_tensor, 'b c (h h2) (w w2) -> b h w c', 'mean', h2=2, w2=2)repeat
- 새로운 axis를 추가하면서, 그 값들을 복사한다.
# copy along a new axis
output_tensor = repeat(input_tensor, 'h w -> h w c', c=3)Configure
!pip install torch
!pip install einopsimport torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary# 테스트용으로 임의의 이미지 tensor를 만든다.
x = torch.randn(8, 3, 224, 224)
x.shapePatch Embedding
먼저 이미지를 patch 단위로 잘라준다.
batch size x channel x height x width로 된 tensor를 batch size x patch 갯수 x patch size로 바꾼다.
patch_size = 16
# batch_size*C*H*W --> batch_size*patch 갯수*패치사이즈 로 바꾼다.
patches = rearrange(x, 'b c (n1 s1) (n2 s2) -> b (n1 n2) (s1 s2 c)',
s1=patch_size, s2=patch_size)
# 이미지를 patch로 나누고 바로 합칠 수 있다.
print('patch shape:', patches.shape)output
patch shape: torch.Size([8, 196, 768])Patch Embedding Using Convolutional Layer
하지만 실제 ViT에서 patch를 나눌 때는, kernel size와 stride size가 patch size와 동일하게 가져가는 convolutional 2D layer를 이용한 후 flatten 시켜준다. 이렇게 하면 performance gain이 있다고 한다.
patch_size = 16
in_channels = 3
emb_size = 768
projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
# flatten
Rearrange('b e h w -> b (h w) e')
)
print('patch size:', projection(x).shape)shape 변화
# (batch size, embedding size, # of patch, # of patch) --> (8, 196, 768)
# (batch size, embedding size, # of patch(세로), # of patch(가로)) --> (batch_size, # of patch, embedding size)
## embeddig size = patch_size x patch_size x channelPatch Embedding Class
- 위에서 구현한 코드를 바탕으로 PatchEmbedding class를 구현한다
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
super().__init__()
self.patch_size = patch_size
# patch embedding layer
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e')
)
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
PatchEmbedding()(x).shapeoutput
torch.Size([8, 196, 768])CLS token
- 위 코드에서 CLS token을 추가한다.
- 논문에서 각 patch를 token이라고 생각하면 된다고 한다.
- 따라서 그림에서 각 패치를 자연어 처리에서의 token이라고 할 수 있고, 이미지 하나를 자연어 처리에서 문장 단위라고 생각하면 좋을 것 같다.
- 그래서 cls token이 문장 앞에 들어간다.
class PatchEmbedding(nn.Module):
def init(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
super().init()
self.patch_size = patch_size
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e')
)
# cls token
self.cls_token = nn.Parameter(torch.randn(1,1,emb_size))
def forward(self, x: Tensor) -> Tensor:
# batch_size
b, _, _, _ = x.shape
# patch embedding
x = self.projection(x)
# batch_size만큼 복사
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# input 앞에 cls token을 붙입니다.
x = torch.cat([cls_tokens, x], dim=1)
return x
PatchEmbedding()(x).shapeoutput
torch.Size(\[8, 197, 768\])Position Embedding
- patch에 대해서 positional embedding을 진행하는 코드를 추가한다.
- 논문에서 positional embedding의 유무와 그 방식에 관해서 성능 비교 실험을 해봤는데, positional embedding을 하는 것은 성능 향상이 있었지만, 방식에 대해서는 차이점이 없었다.
- position information에 대한 관점
- no positional embedding
- 1-dimensional positional embedding: patch를 하나의 긴 sequence로 보는 방식
- 2-dimentional positional embedding: poisition을 x, y의 2차원으로 보는 관점
- Relative poisitional embeddings: transformer의 q,k,v처럼 하나의 patch 대해서 나머지 patch들의 상대적인 위치를 나타내는 방식
- 1-d, 2d positional embedding에서 세가지 케이스로 나눠서 실험
- positional embedding을 encoder에 feed하기 직전에 추가(기존과 같은 방식)
- 각 layer를 시작할 때 positional embedding에 대해서 학습+add
- 두번째 방식과 같지만, layer별로 position 정보들이 공유됨.
- pixel 단위의 transformer에 비해서 patch 단위로 잘라냄으로써 위치 정보에 대한 중요성이 비교적 작기 때문인 것 같다고 저자는 말햇음.
- 논문 기준으로는 standard learnable 1D position embeddings를 썼다고 함.
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768,
img_size: int = 224):
super().__init__()
self.patch_size = patch_size
self.projection = nn.Sequential(
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e')
)
# cls token
self.cls_token = nn.Parameter(torch.randn(1,1,emb_size))
# positions shape: (patch 갯수 + 1(cls token), embedding size)
self.positions = nn.Parameter(torch.randn((img_size // patch_size) ** 2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
# batch_size
b, _, _, _ = x.shape
x = self.projection(x)
# batch_size만큼 복사
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# input 앞에 cls token을 붙입니다.
x = torch.cat([cls_tokens, x], dim=1)
# position embedding
x += self.positions
return x
PatchEmbedding()(x).shapeoutput
torch.Size(\[8, 197, 768\])Transformer
- ViT에서 transformer의 encoder 구조만 쓰인다.
MultiHeadAttention
- query와 key를 통해서 element가 나머지 다른 element에게 얼마나 연관이 있는지를 의미하는 attention weight를 얻을 수 있다.
- value에 attention matrix를 곱해서 값을 조정한다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0.):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# q, k, v 생성 layer
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
# attention dropout
self.att_drop = nn.Dropout(dropout)
# 1/sqrt(d_k)
self.scaling = (self.emb_size // num_heads) ** -0.5
# dense layer
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x: Tensor, mask: Tensor = None) -> Tensor:
# q, k, v
# batch_size, patch_num, emb_size(num_head * d_k)
# --> batch_size, head_num, patch_num, d_k
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), 'b n (h d) -> b h n d', h=self.num_heads)
values = rearrange(self.values(x), 'b n (h d) -> b h n d', h=self.num_heads)
# sum up over the last axis
# query vector x key vector
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
# mksoo 수정
# 원문에서는 softmax 바깥에 scaling이 있었는데, transformer는 scaling 후에 softmax를 취하는 것으로 알고 있다.
att = F.softmax(energy * self.scaling, dim=-1)
att = self.att_drop(att)
# sum up over the third axis
# attention weights * value
out = torch.einsum('bhal, bhlv -> bhav', att, values)
# batch_size, head_num, patch_num, d_k
# --> batch_size, patch_num, emb_size
out = rearrange(out, 'b h n d -> b n (h d)')
# dense layer 통과
out = self.projection(out)
return out
patches_embedded = PatchEmbedding()(x)
MultiHeadAttention()(patches_embedded).shapeoutput
torch.Size(\[8, 197, 768\])원문에서는 qkv를 한 번에 계산하는 과정이 있는데, 그건 skip한다.
Residuals
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return xMLP
- 저자가 forward method 작성 안하려고 그냥 이렇게 작성함.
- 저자도 그냥 해봤는데 되길래 이렇게 작성한다고 함.
- 여기서 GELU는 ReLU + zoneout + dropout을 합친 개념이라고 생각하면 된다.(자세한 내용은 skip)
- 요즘 nlp나 cv에서 많이 쓰이는 activation function 인가봄
class FeedForwardBlock(nn.Sequential): def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.): super().__init__( nn.Linear(emb_size, expansion * emb_size), nn.GELU(), nn.Dropout(drop_p), nn.Linear(expansion * emb_size, emb_size), )
TransformerEncoderBlock
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))Classification Head
분류를 위한 마지막 fc-layer
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
# fc layer에 통과시키기 위해 batch를 빼고 싹 flatten
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))ViT
PatchEmbedding, TransformerEncoder, ClassificationHead를 합쳐서 ViT 구성
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)output
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 768, 14, 14] 590,592
Rearrange-2 [-1, 196, 768] 0
PatchEmbedding-3 [-1, 197, 768] 0
LayerNorm-4 [-1, 197, 768] 1,536
Linear-5 [-1, 197, 768] 590,592
Linear-6 [-1, 197, 768] 590,592
Linear-7 [-1, 197, 768] 590,592
Dropout-8 [-1, 8, 197, 197] 0
Linear-9 [-1, 197, 768] 590,592
MultiHeadAttention-10 [-1, 197, 768] 0
Dropout-11 [-1, 197, 768] 0
ResidualAdd-12 [-1, 197, 768] 0
LayerNorm-13 [-1, 197, 768] 1,536
Linear-14 [-1, 197, 3072] 2,362,368
GELU-15 [-1, 197, 3072] 0
Dropout-16 [-1, 197, 3072] 0
Linear-17 [-1, 197, 768] 2,360,064
Dropout-18 [-1, 197, 768] 0
ResidualAdd-19 [-1, 197, 768] 0
LayerNorm-20 [-1, 197, 768] 1,536
Linear-21 [-1, 197, 768] 590,592
Linear-22 [-1, 197, 768] 590,592
Linear-23 [-1, 197, 768] 590,592
Dropout-24 [-1, 8, 197, 197] 0
Linear-25 [-1, 197, 768] 590,592
MultiHeadAttention-26 [-1, 197, 768] 0
...중략
================================================================
Total params: 86,415,592
Trainable params: 86,415,592
Non-trainable params: 0
Input size (MB): 0.57
Forward/backward pass size (MB): 364.33
Params size (MB): 329.65
Estimated Total Size (MB): 694.56
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] Vision Transformer[1] 논문 정리 (0) | 2023.08.01 |
|---|---|
| [논문리뷰] generative adversarial networks(GAN) (0) | 2023.07.13 |
| [논문리뷰] U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2023.07.04 |
| [논문리뷰] You only look once(YOLO) (0) | 2023.06.29 |
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |