
내용 출처
네이버 부스트코스 딥러닝 기초 다지기 - Gradient Descent Methods
https://www.boostcourse.org/ai111/lecture/1162942?isDesc=false
딥러닝 기초 다지기
부스트코스 무료 강의
www.boostcourse.org
이전 글
https://sept-moon.tistory.com/90
최적화 알고리즘 - gradient descent
경사하강법이란 경사 하강법은 1차 근삿값 발견용 최적화 알고리즘이다. 즉 최적화 알고리즘 중 하나. 기본 개념은 함수의 기울기를 구하고 경사의 반대 방향으로 계속 이동시켜 극소값에 이를
sept-moon.tistory.com
에서 gradient Descent Methods에 대해서 정리했다.
일반적인 GD같은 경우에 문제점이 두 가지 발견할 수 있는데
- 학습률에 대한 이슈
- local minimum 이슈
이다.
번외) Batch size matters
배치 사이즈를 줄이는 것이 일반적으로 성능이 좋다. generalization performance가 좋아짐.
testing function에서의 낮은 loss를 찾는 것이 제일 중요한데, flat minimum, 즉 비교적 둥그스름한 모양의 그래프에서는 일반화 퍼포먼스가 높아짐. 근데, sharp한 minimum에서는 testing에서 약간만 멀어져 있어도 크게 차이가 나는 경우가 있다.

Gradient Descent Method를 돌릴 때, 데이터 양이 커짐에 따라서 메모리의 부담도 커지기 마련인데, 이를 해결하기 위한 방법이 batch로 나눠서 학습하는 것이다.
샘플을 몇 개씩 나누냐에 따라서 총 세 가지로 나뉜다.
- SGD(stochastic gradient descent): 하나의 샘플씩 gradient를 구하고 업데이트 하는 것
- Mini-batch graditent descent: 일정 batch size를 샘플링해서 gradient를 구하고 업데이트 하는 것
- Batch gradient descent: 모든 데이터를 사용해서 gradient를 계산하는 것
다시 본 주제로 넘어가서,
Gradient Descent Methods
- 보통은 라이브러리에서 알아서 해주지만 우리가 직접 optimizer를 골라줘야 하기 때문에, 각각 왜 제안되었고 어떤 성질이 있는지 알아야 한다.
Stochastic gradient descent(SGD)

제일 기본적인 gradient descent
문제점은
- step size(즉, learning rate) 조정하기 힘들다는 점
- local minima
momentum - gradient에 관성(momentum)을 주어 해결한다.

a_t+1 <- β(모멘텀) *a_t(이전의 accumulation) + g_t(gradient)
W_t+1 <- W_t - ηa_t+1
- - local minima를 해결하기 위한 기법
- - 학습 속도가 빨라진다고 한다.
- - 한 번 흘러가기 시작한 gradient를 어느 정도 유지를 시켜준다.
- - 어느 정도 관성을 유지시켜 주기 때문에, gradient의 변화가 크다 해도 어느 정도 균형을 잡아준다고 한다.
- Nesterov Accerated Gradient(NAG)
a_t+1 = βa_t + ∇L(W_t - ηβa_t)
∇L(W_t - ηβa_t) : Lookahead gradient

- - 관성에 의해 local minimum에 빨리 빠지지 못하게 되는 경우가 생긴다.
- - momentum 식과 다른 점은 gradient 항 대신 Lookahead gradient항이 생긴다는 것이다.
- - 한 번 지나간 local minimum을 기억해서 gradient를 계산?
- - momentum은 관성 때문에 봉우리에 conversion 하는게 느린데, NAG는 봉우리에 빠르게 conversion할 수 있다고 한다.
- - 수식을 정확히 이해하지는 못함. 다른 블로그를 찾아 봤을 때, 키워드는 '미리 본다'. '공은 자신이 어디 있는지를 안다'는 정도이다. 정확히 수식적으로 어떤 의미를 뜻하는지는 모르겠다.
Adaptive: step size(learning rate) 문제를 해결한다.
Adagrad

W_t+1 = W_t - η / ( √G_t + ε ) * g_t
- - Adaptive 방법 중 하나
- - 파라미터가 얼마나 지금까지 변해왔는지 파악해서 많이 변한 파라미터에 대해서는 적게 변하게 하고, 적게 변한 파라미터는 많이 변하도록 step size를 조정하는 방식.
- - G_t가 바로 gradient가 얼마나 변했는지 나타내는 것.
- - 입실론을 더하는 것은 0으로 나누는 불상사를 방지
- - G가 무한대로 간다 == 변화율이 커진다 == W의 업데이트를 거의 안해준다.
- - 그래서 너-무 학습이 길어지다 보면, 변화가 점점 없어지는 부작용이 발생한다.
Adadelta

- - Adagrad가 가지는 G_t가 커지는 문제를 보완하는 방향. 현재 타임 스텝 t가 주어졌을 때, window size만큼의 시간에 대한 gradient의 정보를 보면서 G를 조정해주는 방법
- - Gradient는 parameter마다 주어지기 때문에, 만약 parameter가 1,000억개면 gradient 정보도 1,000개 이상이 된다. 이에 100개의 time step에 대한 정보만 갖고 있다 해도, 10조개에 대한 메모리를 차지
- - EMA를 통해서 이를 상쇄시킬 수 있다. 바로 직접 step까지의 g에 대해서 평균을 낸 값이다.
- - EMA: exponential moving average
- - lr이 없어도 학습이 가능한데, 이 말은 우리가 활용할 수 있는 hyper parameter가 사라지는 부작용을 발생시켜 잘 안쓰인다고 한다.
RMSprop

- - 제프 힌턴이 강의에서 발표한 것으로 논문을 통해 제안된 건 아닌데, 실제로 따라해보니 잘된다는... 공식
- - Gradient square에 대한 EMA를 더해준다.
- - H 자리에 단순하게 stepsize를 넣어준다.
Adam

- - 요즘 가장 무난하게 사용하는 방식. 2020년도에도 흔하게 쓰인다고 들었는데, 아직 변함이 없나보다.
- - adaptive 방식 + momentum의 혼합 방식
- - hyperparameters
- - β_1: 모멘텀을 얼마나 유지시킬 것인지
- - β_2: gradient squares에 대한 EMA의 정보.
- - learning rate
- - epsilon
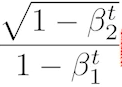
- - 이 수식은 Adam이 unbias해지기 위해 사용하는, 수학적으로 증명된 수식이라고 한다.
- - 실제로는 입실론 parameter가 기본값이 10^-7인가 되는데, 이 값을 잘 바꿔주도록 하는게 실용적으로 중요하다고 한다.
아직 잘 이해되지 않은 부분
- NAG, adadelta, adam
'정리 > Machine Learning' 카테고리의 다른 글
| [논문리뷰] An Image is Worth One Word: Personalizaing Text-to-Image Generation using Textual Inversion (0) | 2023.05.24 |
|---|---|
| [논문 리뷰]cycleGAN - Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (0) | 2023.04.05 |
| [경사하강법] gradient descent (0) | 2023.02.11 |
| RoBERTa 리뷰의 리뷰 (0) | 2022.07.07 |
| Transformer (0) | 2022.07.07 |