
728x90
오늘은
DataCamp 수업 듣고
kaggle에서 pretraining 관련해서 정리된 노트북을 정리해 보았다.
DataCamp 수업은 deeplearning에 대해 간단히 리뷰하는 것이었고, 복습개념으로 들었으며 따로 정리한 것은 없음.
kaggle
출처: https://www.kaggle.com/code/vad13irt/language-models-pre-training/notebook
Language Models Pre-training
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
pretraining 기법들
- pretraining이란 자연어 처리에서 특정 작업에 대해 fine-tuning하기 전에 label이 지정되지 않은 대량의 text data에 대해 언어 모델을 훈련시키는데 사용되는 기술.
- pretraining의 목표는 언어의 구조와 패턴을 학습할 수 있는 모델을 만들어 언어에 대한 깊은 이해를 발전시키고 일관성 있고 상황에 맞는 응답을 생성할 수 있도록 하는 것.
- pretrained LM을 fine-tuning하려면 감정 분석, 텍스트 분류 또는 named entity recognization과 같은 작업에 특정한 더 작은 label이 지정된 dataset에서 모델을 훈련해야 한다.
- google의 BERT(Bidirectional Encoder Representation from Transformers)는 질의 응답, 자연어 추론, 감정 분석 등 다양한 작업에 대해 미세 조정되었으며, 많은 벤치마크에서 SOTA를 달정했고, OpenAI의 GPT-2(Generative Pre-trained Transformer 2) 또한 많은 벤치마킹에서 당시 SOTA를 달성했다.
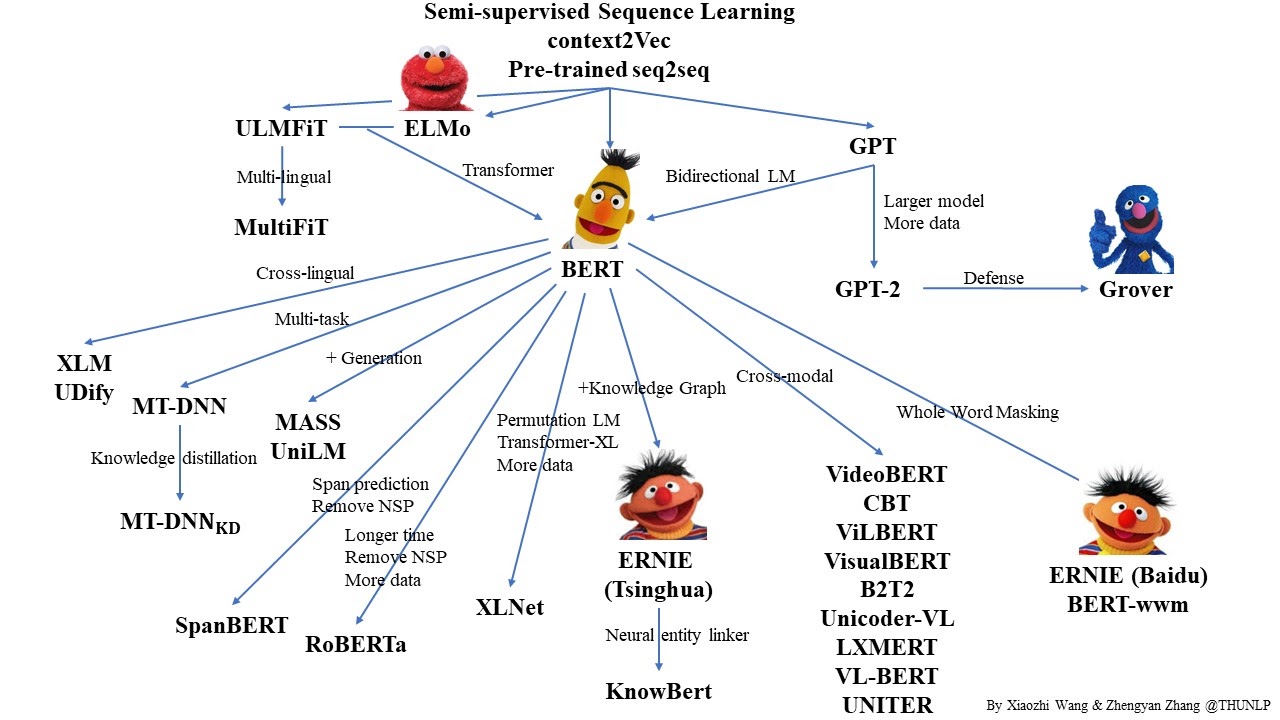
- 방대한 양의 비정형 데이터에 대한 언어 모델 사전 학습을 통해 다양한 자연어 처리 작업에 맞게 미세 조정할 수 있는 다목적(versatile) 모델을 만들 수 있음.
- 소개: Masked Language Models(MLM), Replaced Token Detection(RTD), Sentence Order Prediction, Whole Word Masking(WWM), etc.
Data
- 저자는 LM을 pretraining 할 수 있는 방법을 보여주기 위해 Kaggle 대회의 최신 데이터를 사용할 것.
- 저자는 이 데이터를 활용하여 Masked Language Modeling 및 Replaced Token Detection과 같은 다양한 사전 - 학습 기술과 언어 모델의 정확도를 향상시키는 방법을 보여주고자 한다.
- 시연은 NLP application을 위한 언어 pretraining의 이점을 강조하고 최신 언어 모델을 개발할 수 있는 방법을 보여준다.
pretraining library
- 여기서는 처음보는 pretraining이라는 library를 쓴다.
- library는 MLM, RTD, Sapn masking 등을 포함한 다양한 pretraining 기술을 제공한다.
Pretraining 모델
Causal Language Modeling
- CLM은 token들이 주어졌을 때 다음 token을 예측하는 pretraining technique이다. 이 학습의 목표는 언어의 구조를 이해하고 일관된 자연어 텍스트를 생성하도록 모델을 가르치는 것.
- 사용 모델: GPT, GPT-2, GPT-3, T5 등
- SOTA: language generation, text classification, language translation
Masked Language Modeling
- text sequence에서 일정 비율의 token이 'masked token'이라는 특수한 token으로 대체된 상태에서 사전학습을 진행. 모델은 original token을 예측해야 한다.
- BERT model에서 처음 제안되었음. BERT는 수많은 unstructured text data를 MLM을 활용해 사전학습 되었으며, 이를 통해서 BERT는 질답, 감정분석, 텍스트 분류 등의 다양한 downstream task를 fine-tuning할 수 있게끔 문맥에 맞는 representation을 학습할 수 있음.
- 사용 모델: RoBERTa, ELECTRA, GPT-2. 성능 향상을 위해 각각 약간의 변형을 갖춤.
○ RoBERTa는 dynamic masking과 data augmentation을 사용. ELECTRA는 training process를 개선하기 위해 discriminator generator setup을 사용. GPT-2는 cloze-style이라고 불리는, 모델이 먼저 주어진 토큰에서 다음 토큰을 예측하도록 하는 상황에 MLM을 사용. - 전반적으로, MLM은 언어 모델에 있어서 효과적인 사전학습 technique이다.
- MLM에서 hyperparameter는 masking rate, mask의 type의 비율(MASK, UNK, 다른 단어로 바꾸기), input sequence마다 mask 토큰의 갯수 등이 있다. 최근 연구에서는 MLM에 대한 hyperparameter의 선택이 LM의 성능에 지대한 영향을 미친다고 했다. 예를 들어, "Should You Mask 15% in MLM?"에서 저자는 15%에서 30%까지 masking rate를 늘렸더니 특정 태스크에서 성능이 향상되었다고 했으며, 특히 longer-term dependency에 대한 추론이 그런 경향을 보인다고 한다.
Sentence Order Prediction
- text sequence의 정확한 순서를 예측하는 pretrain technique. sentence의 순서 맞추는 것을 배움으로써 model은 서로다른 문장간의 관계를 캐치할 수 있고, 말이 되는 text을 만들 수 있게 된다.
- 사용 모델: BERT, RoBERTA 등에서 MLM과 같이 쓰임.
- document classification, 감정 분석에서 좋은 성과를 보임.
- 하지만, 몇몇 연구에서는 SOP 그 자체로는 pretraining에 MLM만큼 그렇게 효과를 보이지는 않는다고 했다. SOP를 빼고 pretraining을 진행해 봤을 때, SOP를 넣고 진행하는 것이 전체적으로 퍼포먼스에 영양을 미치지 못한 것이 발견되었다. 그럼에도 불구하고, SOP는 multi-task pretraining setup에 유용한 구성요소이며, model이 text의 구조를 이해하고 text의 서로 다른 파트들을 이해하는데 도움을 준다고 한다.
- SOP pretraining 동안에, 모델은 무작위로 섞인 sentence가 주어졌을 때, sentence의 올바른 순서를 예측해야 한다. 일반적으로 섞인 문장을 단일 텍스트 시퀀스로 연결하고 문장의 경계를 나타내기 위해 각 문장 사이에 특수 구분 기호 토큰(예. [SEP])를 추가하여 수행된다.
- 이전에 RoBERTa나 BERT에서 NSP(next sentence prediction)이라는 이름의 기술을 봤었는데, 아마 같은 기술인 것 같다.(근데 왜 이름이 다른걸까)
Whole Word Masking
- WWM은 MLM과 비슷한데, 이것은 input sequence에서 token 각각이 masking되는 게 아니고 전체 단어가 masking되는 pretraining technique이다.
- WWM에서 input sequence의 단어 하위 집합은 선택되어 특수 mask token으로 대체된다. 그 다음 모델은 주변 단어의 문맥을 기반으로 원래 단어를 예측하도록 훈련된다.
- WWM은 named entity recognition과 같이 word boundary가 중요하거나, 전체 단어를 개별 토큰이 아닌 entity로 식별하는 것이 중요한 task에 효과적인 것으로 나타남. 이러한 경우 MLM은 단어의 일부만 마스킹해서 모델이 named entity의 올바른 boundary를 학습하기 어렵게 만들기 때문에 이런 경우에는 MLM보다 WWM이 더 효과적일 수도 있다.
Replaced Token Detection
- RTD는 어떤 단어가 다른 단어로 대체되었을 때, 대체되었는지 여부를 판단하는데 쓰이는 pretraining technique이다.
- 사용 모델: ELECTRA, DeBERTa v3
- 학습하기 위해 특정 비율의 token이 다른 token으로 대체되고, model은 어떤 token이 바뀌었는지 예측하는 것을 학습한다. RTD pretraining동안에 model은 실제 token과 predicted token과의 loss를 최소화하는 방향으로 학습하게 되는데, 이때 쓰이는 loss function이 binary cross-entropy이다. binary cross entropy는 여기서 예측된 라벨과 실제 라벨의 차이를 계산해 전체 batch에서 계산값을 평균해서 계산된다. model은 loss function을 줄이는 방향으로 학습된다.
- loss function을 최소화함으로써 model은 바뀐 토큰과 바뀌지 않은 토큰을 구분할 수 있게 되며 문맥과 단어간의 관계를 이해하는 능력이 향상된다.
Permutation Language Modeling
- 일부 input token의 순서를 바꾼다음 token의 원래 순서를 예측하도록 모델을 훈련시키는 pretraining technique이다.
- 용도: 자연어 생성과 같이 sequence에서 token 간의 장기적인 종속성을 이해해야 하는 task의 경우 다른 pretraining technique보다 훨씬 좋을 수 있다. token의 원래 순서를 예측하도록 모델을 교육함으로써 다른 pretraining technique으로는 배우기 어려울 수 있는 이러한 long-range dependency를 캐치하는 방법을 학습한다. input의 일부 token을 무작위로 masking하는 MLM과 비교해 PLM은 모델이 input sequence의 모든 token의 올바른 순서를 학습해야 한다. MLM은 local context 및 단어 예측을 학습하는 데 효과적일 수 있지만, PLM은 단어 간의 global dependency와 long term relation를 캐치하는데 더 좋은 것으로 나타났다. 그러나 PLM은 계산 비용이 많이 들 수 있으며 제대로 수행하려면 더 많은 양의 train data가 필요할 수 있다.
Span Masking / Predicting Spans
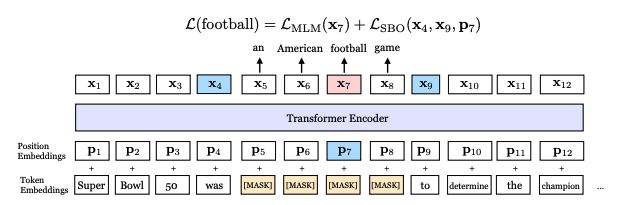
Source: SpanBERT: Improving Pre-training by Representing and Predicting Spans
- Span Masking은 주어진 document에서 text의 span을 예측하는 것과 관련되었다(무슨말?) 이 technique은 종종 언어 모델의 representation의 품질을 개선하기 위해 MLM과 같은 다른 pretraining과 함게 사용된다.
- Span Masking은 named entity, events, 또는 relationship between entity와 같은 downstream task에서 모델이 document의 정보들에 대한 특정 부분을 식별할 때 필요할 수 있다.
- 텍스트의 span을 예측하도록 pretraining함으로써 문서 내에서 중요한 정보를 식별하는 방법을 배우고 해당 정보를 보다 정확하게 표현할 수 있다.
- 예를 들어 named entity recognition task에서 model은 document 내에서 named entity의 언급을 식별하고 분류해야 한다. named entity에 해당하는 text의 span을 예측하도록 모델을 pretraining함으로써 document에서 관련 정보를 식별하고 추출하는 방법을 학습해 downstream task에서 성능을 향상시킬 수 있다.
- 사용 모델: T2, BART와 같은 seq-to-seq 모델
- 전반적으로 Span Masking은 문서 내의 특정 정보를 식별하는 것이 중요한 작업에서 유용하게 쓰일 수 있다. 그러나 document의 전반적인 의미나 구조를 이해하는 데 중점을 둔 task에서는 유용하지 않을 수 있다.
Traslation Language Modeling
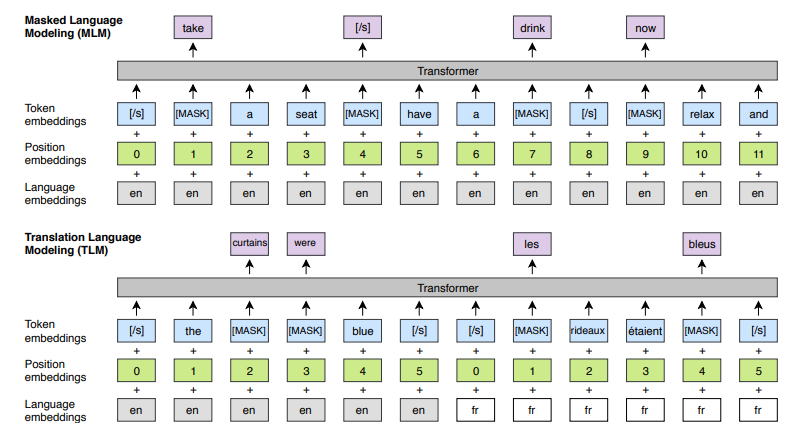
Source: Cross-lingual Language Model Pretraining
- TLM은 최근에 주목을 받이 받는 pretraining technique. Facebook AI Research(FAIR)가 2019년 논문에서 고품질 번역 모델을 train하기 위한 parallel data가 부족한 low-resource language 문제를 해결하기 위한 솔루션으로 제안함.
- TLM은 MLM의 개념을 기반으로 한다. source language와 target language 모두에서 주변 context가 주어지면 문장에서 masking된 token을 예측하기 위해 번역 모델을 사전 훈련하는 작업이 포함된다.
- TLM은 여러 언어로 된 대규모 텍스트 모음에서 model을 pretraining 함으로써 모델이 기계 번역, 다국어 문서 분류 및 다국어 질문-답변을 비롯한 다양한 언어 작업에 사용할 수 있는 다국어 표현을 학습할 수 있도록 한다.
- TLM은 번역 및 기타 언어 작업, 특히 자원이 적은 언어에 대한 효율성과 품질을 개선하는 유망한 결과를 보여 이 분야에 대한 관심과 연구를 증가시켰다.
Contrastive Learning
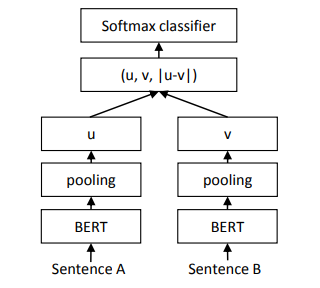
Source: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- Contrastive Learning(CL)은 비지도 학슴의 한 유형으로서, 주어진 dataset에서 유사한 예시와 유사하지 않은 예시를 구별하기 위해 모델을 교육하는 방법이다.
- 목표: 서로 다른 예제 간의 기본 구조 및 관계를 캐치하는 data의 representation을 학습하는 것.
- CL에서 model은 한 쌍의 예에 대해 train되며, 여기서 한 예시는 긍정적인 예시로 간주되고 다른 예시는 부정적인 예시로 간주된다. 모델은 긍정적인 예시 사이의 유사성을 최대화하고 부정적인 예시 사이의 유사성을 최소화하도록 훈련된다.
- CL로 모델을 훈련하려면 먼저 dataset을 선택하고 긍정 및 부정 예제 쌍으로 된 세트를 선택해야 한다. 그 다음 모델은 contrastive loss function을 최대화하도록 훈련되며, 이는 음수 쌍에 대한 높은 유사성 점수와 양수 쌍에 대한 낮은 유사성 점수를 예측하는 모델에 패널티를 준다. training process는 일반적으로 심층 신경망 및 gradient descent optimization을 사용해 대규모 dataset에서 모델을 training하는 작업이 포함된다.
- 모델 예시: Sentence-BERT.
- Sentence BERT에서 사용되는 대조 손실 함수(contrastive loss function)는 모델이 유사한 문장 간의 유사성을 최대화하고 유사하지 않은 문장 간의 유사성을 최소화하는 표현을 학습하도록 권장한다. 이 접근 방식을 통해 Sentence BERT는 문장 간의 의미론적 유사성을 포착하는 문장 임베딩을 생성할 수 있으므로 다양한 자연어 처리 작업을 위한 강력한 도구가 된다.
Tips and Tricks for Pre-training
- 알맞은 데이터셋을 골라라
- data augmentation technique을 활용하라
- 다른 아키텍처에서 실험하라. Transformer-based models, LSTM-based models, CNN-based models 등등. 다른 아키텍처에서 실험하는 것이 특정 task에 최선인 model을 찾는데 도움을 줄 것이다.
- downstream task에 fine tuning
- model을 regularize해라.
- large batch size를 사용하라.
728x90
'진행중' 카테고리의 다른 글
| [TIL] 2023-03-22 gradient descent 정리, back prop 정리 (0) | 2023.03.22 |
|---|---|
| [TID] 2023-03-21 datacamp, kaggle discussion (0) | 2023.03.21 |
| [TIL] 2023-03-17 (0) | 2023.03.18 |
| [TID] 2023-03-13 kaggle notebook 필사 (0) | 2023.03.13 |
| [TIL] 2023-03-09 kaggle notebook review (1) (0) | 2023.03.09 |