
의사결정트리란 의사 결정 규칙과 그 결과들을 트리 구조로 도식화한 의사 결정 지원 도구의 일종이다. (출처. 위키백과)
의사결정나무의 목적
- 한 번에 하나씩의 설명변수를 사용해 정확한 예측이 가능한 규칙들의 집합을 생성
- 최종 결과물은 나무를 뒤집어 놓은 형태인 규칙들의 집합
용어 정리
- 노드.node : 입력 데이터 공간의 특정 영역
- 부모 노드.parent node : 분기 전 노드
- 자식 노드. child node : 부모 노드로부터 분기 후 파생된 노드
- 분기 기준. split criterion: 한 부모 노드를 두 개 이상의 자식 노드들로 분기하는데 사용되는 변수 및 기준 값
- 시작/뿌리 노드. root node: 전체 데이터를 포함하는 노드
- 말단/잎새 노드 leaf node: 더 이상 분기가 수행되지 않는 노드
의사결정나무를 쓰는 이유
- 결과를 사람이 이해할 수 있는 규칙의 형태로 제공
- 데이터의 사전 전처리를 최소화 ( 정규화, 결측치 처리를 안해도 됨)
- 수치형 변수와 범주형 변수를 함꼐 다룰 수 있음
- 초보도 가능!
핵심 아이디어
- 재귀적 분기: recursive partitioning
- 입력 변수의 영역을 두 개로 구분 -> 구분하기 전보다 구분된 뒤에 각 영역의 순도(purity, homogeneity)가 증가하도록
- 가지치기 ( pre-prunning, post-prunning ) : 과적합을 방지하기 위해 너무 자세하게 구분된 영역을 통합
Classification and Regression Tree ( CART )
- 개별 변수의 영역을 반복적으로 분할함으로써 전체 영역에서의 규칙을 생성하는 지도학습 기법
- If_then 형식으로 표현되는 규칙을 생성함으로써, 결과에 대한 예측과 함께 그 이유를 설명할 수 있는 장점
- 수치형 변수와 범주형 변수에 대한 동시 처리 가능


불순도 지표
- 특정한 영역에 개별적인 객체가 얼마나 혼재되어 있는지 알려주는 지표
- 1. 지니계수
c개의 범주가 존재하는 속하는 A영역에 대한 지니 계수

- pk: A영역에 속한 객체들 중 k범주에 속하는 레코드의 비율

= 1 – (pblue) – (pred) = 1 – (6/16)2 – (10/16)2 = 0.4688
- 0 <= I(A) <= 0.5
- 0.5에 가까울수록 순도가 낮다.
두 개 이상 영역에 대한 지니 계수

Ri : 분할 전 레코드(전체 레코드) 중 분할 후 i 영역에 속하는 레코드의 비율

분기 후의 정보 획득 : 0.4688 – 0.3438 = 0.1250
ㄴ 특정 분기 기준의 이득. 얼마나 좋은지를 수치로 표현.
- pk: A영역에 속한 객체들 중 k범주에 속하는 레코드의 비율
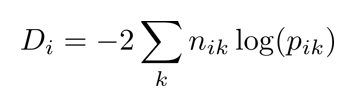
= 1 – (pblue) – (pred) = 1 – (6/16)2 – (10/16)2 = 0.4688
- 0 <= I(A) <= 0.5
- 0.5에 가까울수록 순도가 낮다.
2. Deviance

nik – 범주 안에 있는 특정 레코드의 개수
pik – 범주 안에 있는 특정 레코드의 비율


- 분기 후의 정보 획득(Information gain): 21.17-16.62=4.55
CART: 재귀적 분기 순서
- 한 변수를 기준으로 하여 정렬
- 변수의 정렬 순서, 정렬 기준(오름차순/내림차순)은 최종 모델에 영향을 미치지 않음
- 순차적으로 가능한 분기점에 대한 정보 획득 계산
- 불순도(impurity) 계산: 지니 계수(Gini index)
- 분기 전:

- 분기 후

의사결정나무: 가지치기
- 재귀적 분기는 모든 말단노드의 순도가 100%일때 종료됨
- overfitting 문제. noise도 패턴으로 취급할 수 있음.
- 일반화 성능을 향상시켜야 함.( 새로운 데이터에 대한 예측 성능 저하의 위험을 감소시켜야 )
Post-prunning

- 의사결정나무는 Full Tree를 생성한 뒤 적절한 수준에서 말단 노드를 결합하는 가지치기 수행 (Post-Pruning)
- 검증데이터에 대한 오분류율이 증가하는 시점에서 가지치기
- Full tree에 비해 구조가 단순한 의사결정나무가 생성됨
비용 복잡도(cost complexity) 를 사용하여 최적의 의사결정나무 구조 선택
비용 복잡도(Cost Complexity)
CC(T) = Err(T) + a * L(T)
CC(T) = 의사결정나무의 비용 복잡도 (낮을수록 우수한 의사결정나무)
ERR(T) = 검증데이터에 대한 오분류율
L(T) = 말단 노드의 수 ( 구조의 복잡도 )
a = ERR(T)와 L(T)를 결합하는 가중치 ( 사용자에 의해 부여됨, 일반적인 소프트웨어 패키지에서는 default 값이 존재)
사전적 가지치기( pre-pruning)
- full로 가면서 시간낭비하지 않고, 미리 가지가 자라는 것을 막음
- 제약조건 부여
- 제약조건 예시
- 분기 전후 Information Gain의 최저 기준
- 분기 대상이 되는 노드에 속하는 최소 객체 수
- 의사결정나무가 가질 수 있는 최대 깊이 등
의사결정나무 - 회귀( Regression )
불순도 측정 ( impurity )
sum of squared error ( SSE:

)
- 의사결정나무의 장점
- 의사결정나무는 예측에 대한 설명을 제공할 수 있음
- 변수 선택 과정이 자동적으로 수행됨
- 특별한 통계적 가정을 요구하지 않음
- 결측치가 존재하는 상황에서도 모델 구축이 가능함
- 의사결정나무의 단점
- 한 번에 하나의 변수만 고려하므로 변수간 상호작용을 파악하기 어려움
'정리' 카테고리의 다른 글
| [pandas] Datetime index (0) | 2021.09.01 |
|---|---|
| [210827_라이브 강의] 2. 데이터 전처리-상관관계 분석, 3. 예측모델 구현 (1) | 2021.08.27 |
| [데이터베이스 강의 정리] 9. 성능 (0) | 2021.08.05 |
| [데이터베이스 강의 정리] 8. 백업 및 복구 (0) | 2021.08.05 |
| [데이터베이스 강의 정리] 7. 테이블 설계 (0) | 2021.08.05 |